
面试题1
介绍
大佬背景,44+ offer
美团优选一面
1.项目问题
2、线程池工作流程
线程池就是能够较好管理线程的池子。频繁的创建线程很消耗系统资源,而线程池它能够避免线程的频繁创建和销毁。在线程池中的线程执行完一个线程任务后,当前线程不会立即销毁,它会在线程池中存活一段时间,若在这段时间,线程池中提交了新的任务,就可以直接拿去线程池中的线程,实现了线程的复用。
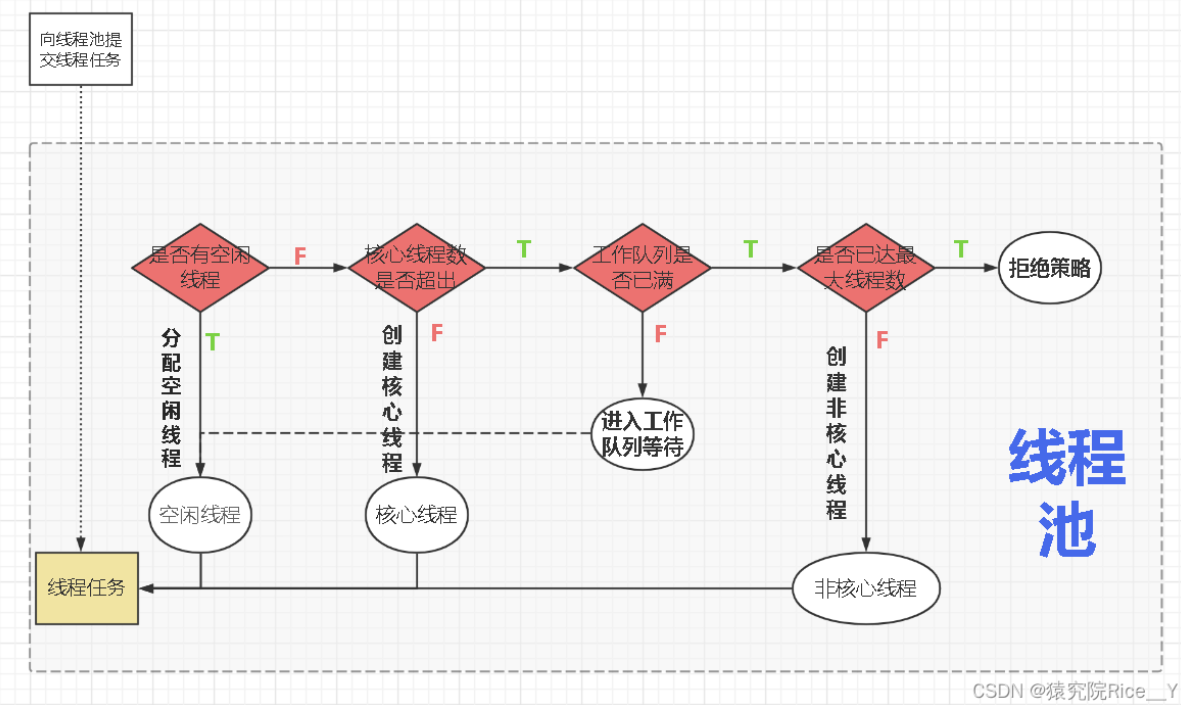
| 概念 | 描述 |
|---|---|
| 核心线程池(Core Pool) | 在线程池中始终保持存活的线程数量。即使它们处于空闲状态,也不会被回收。 |
| 任务队列(Task Queue) | 用于存储等待执行的任务。 |
| 最大线程池大小(Maximum Pool Size) | 线程池中允许存在的最大线程数。当任务队列已满时,新任务会创建新的线程来处理,但不会超过最大线程池大小。 |
| 线程存活时间(Keep Alive Time) | 当线程池中的线程数量超过核心线程数时,多余的线程在空闲一段时间后会被回收。 |
3、线程池实现原理
线程池实现原理包括连接池、内存池等:
- 连接池:缓存数据库连接,避免频繁创建和销毁,提高数据库访问性能。
- 内存池:预分配一块内存池,用于分配和回收内存块,减少内存碎片。
4、Kafka在项目中的实现
Kafka用于异步处理、解耦系统组件,提高系统可伸缩性和容错性。通过定义分区、Topic和Broker来实现水平扩展和数据的持久性。
5、Thrift的使用
Thrift是跨语言的服务框架,通过定义服务接口文件,生成客户端和服务器端代码,实现跨语言的服务调用。
6、Kafka的可靠性保证
Kafka通过分区、Topic和Broker实现可靠性,确保数据的持久性和副本机制。
7、JVM的分配及作用
JVM内存分为堆、栈、方法区等:
- 堆用于存储对象实例。
- 栈用于存储局部变量和方法调用信息。
- 方法区用于存储类信息。
8、垃圾回收的几种算法
垃圾回收算法包括标记-清除、复制、标记-整理、分代垃圾回收。
9、CMS是怎么实现的
CMS(Concurrent Mark-Sweep)使用并发标记-清除算法,减少停顿时间。
10、CMS在并发标记中出现STW的时候
用户可以在CMS的参数中调整并发标记阶段的并发度,以控制STW的时间。
11、CMS使用的垃圾回收算法
CMS使用标记-清除算法。
12、为什么G1垃圾回收器好
G1垃圾回收器有更可预测的停顿时间、更高的吞吐量、更低的内存占用。
13、G1和CMS的区别
G1是分代垃圾回收器,适用于大堆,有更可控的停顿时间;CMS是非分代垃圾回收器,适用于中小堆。
14、Redis作用
Redis是高性能的键值存储系统,用于缓存、消息中间件、计数器、排行榜等应用场景。
15、Redis为什么快
Redis快的原因包括内存存储、单线程的事件驱动模型,避免了多线程竞争。
16、Redis的单线程指的是什么
Redis的单线程指的是主要的网络IO和数据操作都在一个线程中进行。
17、Redis有什么缺点
缺点包括持久化成本高、对内存需求较大、单线程可能在高并发场景下有瓶颈。
18、Redis的缓存雪崩、穿透、击穿及解决方案
- 缓存雪崩:大量缓存同时失效,导致请求直接落到数据库。
- 解决方案:设置不同的过期时间,加入随机性。
- 缓存穿透:恶意请求查询缓存中不存在的数据,导致请求直接落到数据库。
- 解决方案:使用布隆过滤器,拦截不存在的请求。
- 缓存击穿:某个热点数据过期,导致大量请求直接落到数据库。
- 解决方案:使用互斥锁,只允许一个请求重新生成缓存。
19、MySQL索引使用的原则
MySQL索引使用原则包括最左匹配原则、避免使用%前缀模糊查询。
20、何时创建索引
需要加速查询速度、降低排序和聚合操作成本、提高唯一性约束时创建索引。
21、MySQL隔离级别
MySQL隔离级别包括读未提交、读已提交、可重复读、串行化。默认使用可重复读。
22、MySQL实现可重复读和MVCC使用过程
MVCC通过保存数据在某个时间点的快照来实现可重复读,避免了读未提交和读已提交问题。
23、MySQL事务底层原理
MySQL事务底层原理涉及undo log、redo log等,用于实现事务的持久性和隔离性。
24、MQ的好处及为何使用MQ
MQ提供异步解耦、削峰填谷、可靠消息传递等好处。使用MQ可以提高系统可伸缩性、灵活性和可靠性。
到家一面
1、聊了一下项目
项目讨论可能涉及项目的业务逻辑、技术栈、挑战和解决方案等方面,是了解面试者实际经验的重要环节。
2、虚拟内存解释
虚拟内存是一种计算机系统的内存管理技术,它使得应用程序认为它拥有连续可用的内存,而实际上,这些内存可能来自于物理内存(RAM)、硬盘上的交换文件等。虚拟内存的存在提高了系统的多任务处理能力和内存利用率。
3、线程池内容
线程池是一种管理和复用线程的机制,通过线程池可以减少线程的创建和销毁开销。常见的线程池包括FixedThreadPool、CachedThreadPool、ScheduledThreadPool等。
4、美团内部Renio线程池框架源码
涉及美团内部的具体技术实现,需要深入研究美团的Renio线程池框架源码,了解其设计和实现原理。
5、Java类加载过程
Java类加载过程包括加载、连接(验证、准备、解析)和初始化三个阶段。加载阶段加载类的二进制数据到内存,连接阶段对类进行验证、准备和解析操作,初始化阶段执行类的初始化代码。
6、静态代码块、普通代码块、构造方法执行顺序
执行顺序为静态代码块 → 普通代码块 → 构造方法。静态代码块在类加载时执行,普通代码块在对象创建时执行,构造方法是对象创建后调用。
7、为什么要有HashCode
HashCode用于提高数据的检索效率。在哈希表等数据结构中,通过HashCode可以快速定位到数据的存储位置,减少了查找的时间。
8、HashCode是做什么用的
HashCode主要用于在哈希表中定位对象的存储位置,提高查找效率。在Java中,HashCode被用于HashMap等集合的实现中。
9、HashMap使用get的时候流程
HashMap使用get方法时,首先根据Key的HashCode找到对应的桶(Bucket),然后在桶内通过Key的equals方法找到对应的Entry,最终获取到对应的值。
10、HashMap使用put的过程是怎么实现的
HashMap使用put方法时,先根据Key的HashCode找到对应的桶,然后在桶内通过Key的equals方法查找是否存在相同的Key。如果存在相同的Key,则更新对应的值;如果不存在相同的Key,则在桶中添加新的Entry。
11、如果结构不是Hash结构的话可不可以直接使用equals方法
如果结构不是Hash结构,直接使用equals方法可能会导致线性查找的时间复杂度较高,效率低下。通常,在需要频繁查找的情况下,使用Hash结构能够提高查找效率。
12、MySQL中MVCC机制
MVCC(Multi-Version Concurrency Control)是MySQL数据库中实现事务隔离级别的机制。通过保存数据在某个时间点的快照,实现了读写并发操作的隔离性。
16、DNS过程
DNS(Domain Name System)解析过程包括递归查询和迭代查询,最终将域名映射为IP地址。
17、ThreadLocal存储结构
怎么存储的
ThreadLocal是一种线程封闭的变量存储结构,每个线程都有自己的ThreadLocal变量副本。存储通过ThreadLocalMap实现,每个线程维护一个Map,其中存储各自的ThreadLocal变量。
18、强弱软虚四种引用
强引用(Strong Reference)、弱引用(Weak Reference)、软引用(Soft Reference)、虚引用(Phantom Reference)是Java中用于描述对象可达性的不同级别。
19、深浅拷贝
深拷贝和浅拷贝涉及对象复制。浅拷贝是复制对象,但不复制对象的内容;深拷贝是复制对象和对象的所有内容。
京东一面
1、拷打项目
可能是指了解项目的一些情况,业务逻辑、技术栈、挑战和解决方案等。
2、Kafka高可用
Kafka高可用通常通过多个Broker、分区的复制和副本机制来实现。通过分布式架构和数据冗余,确保Kafka集群在部分节点故障时仍然可用。
3、synchronized的实现原理
synchronized通过Java对象头中的Mark Word实现,包括偏向锁、轻量级锁和重量级锁。具体实现原理涉及对象的状态切换和线程的竞争。
4、synchronized和Lock的区别
synchronized是Java关键字,是基于JVM实现的;Lock是Java类库提供的接口,是基于Java代码实现的。synchronized是悲观锁,每次获取锁都需要检查状态;Lock是乐观锁,通过CAS操作尝试获取锁。synchronized是可重入锁,同一线程可以多次获取同一把锁;Lock也是可重入锁,但需要手动释放锁。
6、为什么会产生死锁
死锁产生的原因是多个线程相互等待对方释放资源,形成一个循环等待的状态。
7、你设计的话如何避免死锁
避免死锁的方法包括破坏死锁的四个必要条件:互斥条件、不可剥夺条件、请求与保持条件、环路等待条件。可以使用加锁顺序、超时机制、死锁检测等方式来避免死锁。
8、synchronized的锁升级过程
synchronized锁升级过程包括无锁状态、偏向锁、轻量级锁和重量级锁。锁升级的目的是为了在不同场景下提供最优的性能。
9、CMS和G1的区别
CMS(Concurrent Mark-Sweep)和G1(Garbage First)都是Java垃圾回收器,区别在于CMS主要优化老年代,G1则是分代收集器,更加均衡地管理整个堆内存。
10、MySQL相关问题
可能涉及MySQL的索引、事务、存储引擎、优化等方面的常见问题。
11、Redis为什么是单线程
Redis采用单线程模型主要是为了避免多线程下的竞态条件和锁的开销,提高性能。单线程模型通过高效的事件循环和非阻塞I/O实现高并发。
12、Redis分布式锁
Redis分布式锁可以通过SETNX(SET if Not eXists)指令实现,或者使用RedLock等算法实现分布式锁。
13、分布式锁的缺点
分布式锁的缺点包括性能开销、可用性问题、死锁等。需要权衡性能和一致性的需求。
14、解决不好确定分布式锁时间的问题
可以使用超时机制、续租机制、自适应时间等方式来解决不确定分布式锁时间的问题。
15、Redisson框架
Redisson是一个基于Redis的Java驱动框架,提供了丰富的分布式功能,如分布式锁、分布式对象、分布式集合等。看门狗机制用于实现分布式锁的自动续租。
16、设计处理大量请求的方式
具体设计可能包括使用负载均衡、分布式缓存、异步处理等策略。
17、令牌桶方式解决
令牌桶是一种限流算法,通过控制令牌的发放速率,限制请求的频率,以保护系统免受过载。
18、MQ的好处
MQ提供异步解耦、削峰填谷、可靠消息传递等好处,提高系统的可伸缩性和可靠性。
19、设计高可用的初始化服务
高可用的设计可能包括主从复制、负载均衡、故障转移、数据备份等措施。
20、大量请求的服务部署
可能涉及水平扩展、微服务架构、负载均衡等手段来应对大量请求。
21、Redis大Key的解决
可能采用分片、分区、数据拆分等方式来解决Redis中大Key的问题。
22、Redis中打散大Key的查找方式
除了管道,还可以使用分布式哈希等方式,将大Key拆分为多个小Key,分布在多个节点上,从而提高查询效率。
23、线程池的工作流程
线程池工作流程包括任务提交、任务排队、线程分配、任务执行等步骤,通过复用线程资源提高性能。
24、理解CompletableFuture的底层实现原理
CompletableFuture是Java中用于异步编程的工具,基于Future和
Promise模式,实现了异步任务的提交、执行和结果获取等操作。
25、处理子线程工作完成的方式
使用CountDownLatch或CompletableFuture等方式等待子线程完成工作,确保主线程在子线程完成后再执行。
这些问题涉及了广泛的Java基础、并发编程、分布式系统和框架等知识点。在准备面试时,建议对这些问题进行深入的理解和准备。
京东二面
Spring中的自定义注解是通过@interface关键字来定义的。使用中文解释一下自定义注解的基本概念和使用方法:
自定义注解是一种Java语言的特殊标记,可以在类、方法、字段等程序元素上添加元信息,用于在运行时提供额外的信息或配置。Spring框架中,自定义注解通常用于标记某些类、方法或字段,以便在运行时通过反射获取这些标记,进行特定的逻辑处理。
自定义注解的定义形式类似于接口,使用@interface关键字,如下所示:
import java.lang.annotation.ElementType; |
上述代码定义了一个名为MyCustomAnnotation的自定义注解,包含两个属性:value和priority,分别是字符串类型和整数类型。通过@Target注解指定了该注解可以被应用在类和方法上,通过@Retention注解指定了该注解在运行时可见。
在使用自定义注解时,可以将它应用在类、方法或字段上,如下所示:
|
在上述示例中,MyClass类和myMethod方法都被MyCustomAnnotation注解标记,并通过注解的属性传递了相应的值。
在实际应用中,Spring框架通过扫描类路径或配置文件等方式,发现并处理使用了自定义注解的类、方法等元素,实现特定的功能,比如AOP切面、组件扫描、事务管理等。
得物一面
3、Thrift序列化了解吗,怎么实现的
Thrift是一个跨语言的序列化框架,通过定义IDL(Interface Definition Language)描述数据结构和服务,然后通过Thrift编译器生成不同语言的代码。Thrift序列化通过二进制协议实现,将结构化的数据编码为字节流,以便在网络传输或存储中使用。
4、Thrift为什么是二进制,有啥好处,序列化反序列化咋弄的
Thrift选择二进制协议的主要好处是效率高,序列化后的数据体积小,传输速度快。序列化过程是将结构化的数据按照定义的IDL规则编码为字节流,而反序列化则是将字节流解码还原为原始的数据结构。
5、Redis大Key问题,为啥慢,主要影响了什么
Redis中的大Key会导致性能下降,因为在操作大Key时,Redis需要将整个大Key加载到内存中,导致内存占用高、操作时间长。这会影响系统的响应速度,降低了Redis的性能表现。
6、如何解决大Key
解决大Key问题的方式包括数据拆分、分区、使用Hash数据结构、定期清理等。具体的解决方案取决于业务场景和数据访问模式。
7、你是怎么优化大Key的
可能涉及到具体的业务场景和技术方案,优化大Key的方式可以包括拆分数据、使用分布式存储、缓存策略等。
10、SQL执行过程
SQL执行过程包括语法解析、语义分析、查询优化、执行计划生成、执行计划执行等多个阶段。
11、我给SQL字段创建了索引,是怎么查的
在查询时,数据库优化器会根据索引选择合适的执行计划,以提高查询性能。通过使用索引,数据库可以快速定位符合查询条件的记录。
12、如果返回的是ID + 索引列,怎么查询
具体查询可能涉及到关联查询、使用聚合函数等,具体取决于查询的业务需求。
13、B+索引比Hash索引、B树索引、二叉索引好的点
B+树索引相对于Hash索引、B树索引和二叉树索引的优势包括范围查询效率高、有序性好、支持顺序遍历等。
14、讲讲MVCC机制怎么实现的隔离级别
MVCC(多版本并发控制)机制通过在数据库中保存多个版本的数据实现事务的隔离。不同数据库的实现方式有所不同,但主要包括版本号、UndoLog、ReadView等元素。
15、RedoLog、UndoLog作用是啥对应ACID哪个板块,在执行一个SQL的过程中怎么使用的
RedoLog用于记录事务的操作,用于保证事务的持久性,属于事务的Durability(持久性)属性。UndoLog用于实现事务的隔离和回滚,属于事务的Isolation(隔离性)属性。在SQL执行过程中,RedoLog和UndoLog用于恢复和回滚事务。
16、Spring的异常处理机制是怎么处理的
Spring的异常处理机制通过@ExceptionHandler、HandlerExceptionResolver等实现,可以在Controller层或全局进行异常处理,返回友好的错误信息或页面。
17、线程池的原理
线程池通过预先创建一定数量的线程,将任务提交到线程池中执行,以避免频繁地创建和销毁线程。原理包括任务队列、线程池管理器、工作线程等组成。
18、线程池7大核心参数、拒绝策略、工作流程
线程池的7大核心参数包括核心线程数、最大线程数、线程空闲时间、任务队列、拒绝策略等。拒绝策略用于处理当线程池满员时无法处理新任务的情况。工作流程包括任务提交、线程池状态判断、线程创建或复用、任务执行等过程。
19、为什么不使用newThread的方式创建线程,缺点是什么
使用new Thread的方式创建线程每次都会创建一个新的线程对象,造成线程的频繁创建和销毁,开销较大。而线程池通过复用线程对象,减少了线程创建和销毁的开销,提高了性能。
途虎养车(武汉)一面
3、MySQL底层索引结构
除了B+树索引,MySQL还支持哈希索引。InnoDB引擎的主要索引结构是B+树,而MEMORY引擎则支持哈希索引。MyISAM引擎的索引结构也包括B+树和全文索引。不同存储引擎对索引的实现方式有所不同。
4、情景题,判断行锁表锁
行锁和表锁是MySQL中的两种锁定方式。行锁是针对表中的某一行数据的锁,而表锁则是锁定整个表。判断使用行锁还是表锁通常取决于事务的隔离级别、具体业务需求和性能考虑。在高并发的情况下,更倾向于使用行锁,以减小锁的粒度,提高并发性能。
5、优化慢SQL
优化慢SQL可以通过分析执行计划,使用合适的索引,避免全表扫描,合理使用缓存,优化复杂查询等方式。另外,可以通过使用数据库性能分析工具,如EXPLAIN语句、慢查询日志等,来定位和解决性能瓶颈。
6、消息队列的一些八股
消息队列是一种解耦系统各个组件的通信方式,常见的消息队列有Kafka、RabbitMQ、ActiveMQ等。相关八股可能涉及消息生产者、消费者、消息中间件、消息确认机制、消息重试、死信队列等。
7、Spring IOC和AOP内容
Spring的IOC(Inversion of Control)是一种设计模式,通过将对象的创建和依赖关系管理交给Spring容器来实现。AOP(Aspect-Oriented Programming)是一种编程范式,通过在不改变业务逻辑的前提下,横切关注点,提供可重用的模块化功能。在Spring中,AOP通过代理机制实现。
8、自动装配
自动装配是Spring框架中的一个特性,通过在配置文件中配置<context:component-scan>,Spring容器会自动扫描并注册符合条件的Bean,避免手动一个个配置Bean的繁琐过程。自动装配的方式包括按类型自动装配、按名称自动装配、构造器注入、setter方法注入等。
9、Redis为什么快
Redis之所以快,主要因为它是基于内存的数据存储系统,所有的数据都存储在内存中,避免了磁盘I/O的开销。此外,Redis采用了高效的数据结构和算法,支持丰富的数据操作,如字符串、哈希表、列表、集合、有序集合等。其单线程模型也简化了并发控制,避免了多线程之间的锁竞争。
10、项目中Redis使用,怎么设计的Key
在项目中使用Redis时,设计Key需要考虑唯一性、可读性和易管理性。常见的设计方式包括使用业务标识+具体数据标识构建Key,避免Key冲突。同时,可以利用Redis的数据结构,如Hash、Set等,将复杂的数据结构拆分为多个Key,提高数据的可维护性和扩展性。
11、网易实习过程中都出过什么问题
这是根据个人经历的问题,可能包括项目经验、技术难题、团队协作等方面的问题。回答时可以分享在实习过程中遇到的挑战和解决方案。
12、Java的一些简单八股
可能涉及Java基础知识,如多线程、集合、异常处理、IO流等。八股题一般是对Java基础知识的综合考察。
以上问题涉及的知识点较多,建议根据实际经验和知识储备进行深入准备。
用友科技SP面试
2、Spring Bean加载过程
Spring Bean的加载过程包括:
- 定位:根据配置文件或注解定位到Bean的定义。
- 加载:通过反射或CGLIB等方式创建Bean的实例。
- 注册:将Bean的定义注册到Spring容器中。
- 初始化:执行Bean的初始化方法,可以通过
init-method指定。 - 使用:Bean可以被其他Bean或者容器本身使用。
- 销毁:当Bean不再被需要时,执行销毁方法,可以通过
destroy-method指定。
3、解决循环依赖
循环依赖是指两个或多个Bean相互依赖形成一个循环。Spring解决循环依赖有两个阶段:
- 构造器注入阶段:Spring先通过构造器注入完成对象的实例化,然后将未初始化的对象提前暴露给Spring容器,解决循环依赖。
- 属性注入阶段:Spring完成所有Bean的构造器注入后,再通过属性注入完成剩余的依赖注入。
4、FactoryBean和BeanFactory的区别
- FactoryBean:是一个接口,用户可以实现该接口定义自己的工厂类,通过该工厂类可以创建对象实例。用户在配置文件中定义的Bean实际上是FactoryBean的实现类,通过
getObject方法返回实际的Bean实例。 - BeanFactory:是Spring IoC容器的顶层接口,定义了容器的基本行为。它包含了很多不同类型的Bean,例如
ListableBeanFactory、HierarchicalBeanFactory等。
5、Spring AOP和IOC区别
- AOP(面向切面编程):主要用于在不改变原有代码的情况下,通过对方法的拦截和增强,实现横切关注点的功能。AOP通过动态代理或字节码增强实现。
- IOC(控制反转):是一种设计思想,由Spring容器负责创建、组装和管理对象,降低了组件之间的耦合度。IOC通过依赖注入实现。
6、自动装配实现原理
自动装配通过@Autowired注解实现,Spring容器会自动在容器中找到匹配类型的Bean进行注入。实现原理包括AutowiredAnnotationBeanPostProcessor后置处理器,通过Bean的类型和名称进行匹配。
7、JDK和JRE区别
- JDK(Java Development Kit):是Java开发工具包,包含了Java的开发工具和Java的运行环境。用于开发Java应用程序。
- JRE(Java Runtime Environment):是Java运行环境,包含Java虚拟机(JVM)、类库和其他一些支持Java程序运行的文件。用于运行Java应用程序。
8、三大特征
Java的三大特征分别是:
- 面向对象:封装、继承、多态。
- 平台无关性:Java程序可以在不同平台上运行。
- 分布式计算:支持网络编程,可以通过远程方法调用(RMI)实现分布式计算。
9、MySQL八股
MySQL的八股可能涉及MVCC、索引失效、慢SQL的优化等。MVCC是MySQL数据库实现高并发的一种机制,索引失效涉及到查询语句的性能优化,慢SQL优化需要通过分析执行计划等方式。
10、Redis怎么用
使用Redis主要包括连接Redis服务器、设置和获取数据、使用不同的数据结构、配置持久化等。常见的用法有字符串操作、哈希表、列表、集合、有序集合的使用,以及使用发布/订阅模式等。
11、JVM的垃圾回收算法
JVM的垃圾回收算法包括标记-清除、复制、标记-整理等。CMS(Concurrent Mark-Sweep)和G1(Garbage First)是两种不同的垃圾回收器,CMS以减小垃圾回收停顿时间为目标,G1则更加注重整体吞吐量和可预测的停顿时间。
信也科技(菲律宾)一面
3、MySQL优化,索引失效
MySQL优化涉及到多个方面,其中索引是重要的优化手段之一。索引失效可能由于以下原因:
- 未命中索引:查询条件中的字段没有建立索引。
- 使用函数:在查询条件中使用了函数,导致无法使用索引。
- 范围查询:在索引列上使用了范围查询,如
<>、!=等。 - 数据分布不均匀:导致索引失效,如数据倾斜。
4、Spring Bean的生命周期
Spring Bean的生命周期包括:
- 实例化:容器根据Bean的定义创建Bean的实例。
- 属性注入:通过依赖注入设置Bean的属性。
- 初始化:调用
@PostConstruct注解的方法或实现InitializingBean接口的afterPropertiesSet方法。 - 使用:Bean可以被其他Bean或者容器本身使用。
- 销毁:调用
@PreDestroy注解的方法或实现DisposableBean接口的destroy方法。
5、线程池使用
线程池用于管理和复用线程,提高多线程应用程序的性能和稳定性。常用的线程池有ThreadPoolExecutor和ScheduledThreadPoolExecutor。通过Executors工厂类可以方便地创建不同类型的线程池。
6、怎么使用线程池
使用线程池的步骤包括:
- 创建线程池:通过
ExecutorService接口的工厂方法创建线程池。 - 提交任务:将任务提交给线程池,可以是
Runnable或Callable类型的任务。 - 执行任务:线程池会自动选择合适的线程执行任务。
- 关闭线程池:在不需要线程池时关闭,调用
shutdown方法。
7、怎么设计线程池参数
线程池的参数设计包括:
- 核心线程数:最小的线程数,即使空闲也不会被回收。
- 最大线程数:线程池中最多能拥有的线程数。
- 工作队列:存放尚未执行的任务,有
LinkedBlockingQueue、ArrayBlockingQueue等。 - 线程存活时间:在核心线程外的线程空闲时间超过这个时间就会被回收。
- 拒绝策略:当工作队列和最大线程都满了,新任务的处理方式。
8、缓存穿透解决方案
缓存穿透是指查询一个一定不存在的数据,导致缓存无效,每次都要访问数据库。解决方案包括:
- 空对象缓存:将查询为空的结果缓存起来,下次查询相同的Key直接返回空结果,避免对数据库的频繁查询。
- 布隆过滤器:对查询的Key进行布隆过滤器判断,如果不在布隆过滤器中,直接拦截,避免对缓存和数据库的查询。
9、缓存击穿解决方案和布隆过滤器
缓存击穿是指一个Key非常热点,当这个Key在缓存中过期时,大量的请求直接访问数据库。解决方案包括:
- 加锁:在查询数据库的代码段加锁,确保只有一个线程查询数据库,其他线程等待。
- 布隆过滤器:在缓存层面使用布隆过滤器,对查询的Key进行过滤,不在布隆过滤器中的Key直接拦截,避免对
网易有道一面
2、Kafka的可靠性
Kafka通过以下机制来保证可靠性:
- 复制机制:Kafka使用分区副本机制,将同一分区的数据复制到多个Broker上,确保数据的冗余存储。
- ISR(In-Sync Replica)机制:保证数据在所有副本中的同步。只有处于ISR列表中的副本才能被选举为Leader,确保了写入的可靠性。
- Leader选举:当Leader不可用时,Kafka会从ISR列表中选择新的Leader。
- 消息确认机制:生产者可以选择同步发送(等待所有副本都确认收到消息后才返回)或异步发送(不等待确认),根据业务需求选择适当的确认机制。
3、Kafka生产者确认机制
Kafka生产者的确认机制分为三种:
- acks=0:生产者不等待任何确认,直接发送下一条消息。
- acks=1:生产者等待Leader确认消息写入成功后返回,不等待ISR中的所有副本确认。
- acks=all:生产者等待ISR中的所有副本都确认消息写入成功后返回。
4、Kafka中Broker、分区、Topic的概念
- Broker:Kafka集群中的每个服务器节点就是一个Broker,负责存储数据、处理生产者和消费者请求。
- 分区:每个Topic可以分为多个分区,每个分区存储部分数据。分区有助于水平扩展和提高并发性。
- Topic:消息的逻辑类别,每个Topic可以有多个分区,每个分区可以有多个副本。
5、Kafka中消息的Key作用
消息的Key在Kafka中用于决定消息被发送到哪个分区。如果消息有Key,Kafka会根据Key使用哈希算法将消息路由到一个固定的分区,保证具有相同Key的消息被写入同一个分区。这有助于保证具有相同Key的消息按顺序被消费。
6、场景题:消息消费失败后继续消费的设计
设计方案可以包括以下几点:
- 消息重试:在消息消费失败后,重新发送消息到消费队列,进行重试。
- 死信队列:将消费失败的消息放入死信队列,定期重新尝试消费。
- 异常处理:在消费者中进行异常处理,记录日志,确保消费失败的消息不会导致整体消费过程中断。
7、Kafka为什么吞吐量那么高
Kafka实现高吞吐量的原因包括:
- 顺序写磁盘:Kafka采用追加写方式,消息写入时是追加到文件末尾,减少了磁盘寻址的开销。
- 零拷贝机制:Kafka通过sendfile系统调用,避免了数据在内核态和用户态之间的复制,提高了性能。
- 分区机制:Kafka允许数据水平分割,每个分区可以在不同的Broker上,实现水平扩展。
- 副本机制:数据的冗余存储,保证了数据的可靠性,即使某个Broker宕机,其他Broker上的副本仍然可用。
8、零拷贝机制
零拷贝是一种减少数据复制次数,直接在内核态进行数据传输的机制。在Kafka中,零拷贝通过sendfile系统调用实现,将数据从文件系统复制到网络套接字,避免了在用户态和
 微信
微信- 支付宝



