瑞吉外卖全栈解释 POM(Project Object Model)
Maven
Maven是一个用于构建和管理Java项目的强大工具和项目管理工具链。它提供了一种规范化的项目结构、一套标准化的构建生命周期和一系列丰富的插件,使得项目的构建、依赖管理和部署变得更加简单和可靠。
数据库配置 url datasource: druid: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/reggie?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true username: root password: 111111
介绍 这段代码是一个MySQL数据库连接的URL,其中包含了一些参数和配置选项。让我逐个解释这些参数的含义:
jdbc:mysql://localhost:3306/reggie: 这是数据库的连接地址。jdbc表示使用JDBC连接方式,mysql表示数据库类型,localhost表示数据库服务器的主机名,3306表示MySQL服务的默认端口号,reggie是数据库的名称。
?serverTimezone=Asia/Shanghai: 这个参数用于设置数据库的时区,将其设置为”Asia/Shanghai”表示使用上海的时区。
&useUnicode=true: 这个参数指定使用Unicode字符集。
&characterEncoding=utf-8: 这个参数指定使用UTF-8字符编码。
&zeroDateTimeBehavior=convertToNull: 这个参数指定当数据库中的日期时间字段为零值(”0000-00-00”)时的处理方式,将其转换为NULL值。
&useSSL=false: 这个参数用于指定是否使用SSL加密连接。在这里,设置为false表示禁用SSL。
&allowPublicKeyRetrieval=true: 这个参数用于指定是否允许从数据库获取公钥。在这里,设置为true表示允许获取公钥。
utf8mb4 utf8mb4是一种字符编码,用于支持存储和处理包含四字节字符(如表情符号)的Unicode字符集。它是对传统的UTF-8编码进行扩展,以便能够正确表示和处理更广泛的字符范围。
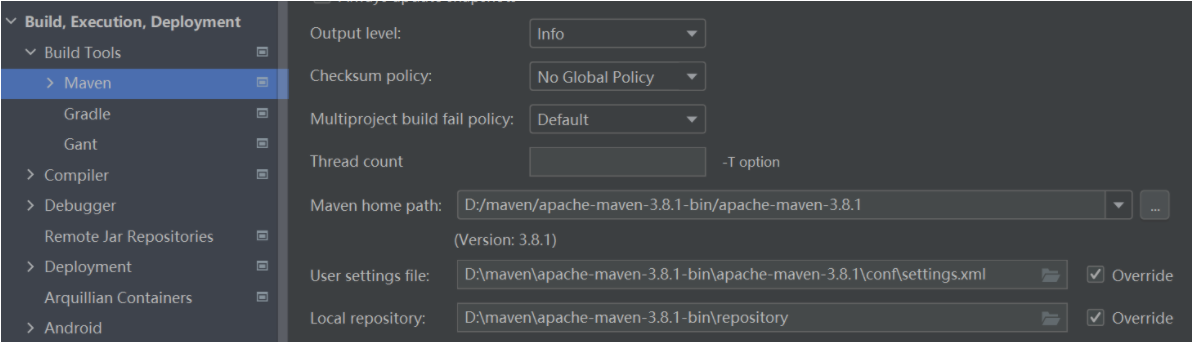
创建maven项目后,一定要检查项目的编码,maven仓库的配置,jdk的配置等;
redis 在Spring中,spring.redis.database属性用于指定要使用的Redis数据库的索引。Redis数据库是一个键值存储系统,其中数据以键值对的形式存储在内存中。每个Redis实例可以包含多个数据库,通过索引来区分不同的数据库。
默认情况下,Redis实例包含16个数据库,索引从0到15。通过设置spring.redis.database属性,可以指定要使用的数据库索引。例如,spring.redis.database: 1表示使用索引为1的Redis数据库。
MyBatis-Plus配置项 log-impl: org.apache.ibatis.logging.stdout.StdOutImpl 是 MyBatis-Plus 中的一个配置项,用于指定 MyBatis-Plus 在记录日志时所使用的日志实现类。
常用库 <dependency > <groupId > com.alibaba</groupId > <artifactId > druid-spring-boot-starter</artifactId > <version > 1.1.23</version > </dependency >
spring-boot-starter: 提供了 Spring Boot 应用程序的基本依赖,包括 Spring 核心功能、自动配置和开发工具。
spring-boot-starter-test: 提供了在 Spring Boot 应用程序中进行单元测试和集成测试的支持,包括 JUnit、Mockito 等测试框架和工具。
spring-boot-starter-web: 提供了构建基于 Spring MVC 的 Web 应用程序所需的依赖,包括 Servlet、Tomcat 等。它简化了开发 Web 应用程序的过程。
mybatis-plus-boot-starter: 提供了 MyBatis-Plus 的 Spring Boot 集成支持,简化了 MyBatis 的配置和使用。MyBatis-Plus 是一个基于 MyBatis 的增强工具,提供了更简洁的 API 和便捷的 CRUD 操作。
lombok: 是一个 Java 库,通过注解来减少 Java 代码中的冗余,简化了实体类的编写和 Getter/Setter 方法的生成。
fastjson: 是一个高性能的 JSON 解析和序列化库,用于处理 JSON 数据。
commons-lang: 是 Apache Commons 项目中的一个库,提供了许多常用的工具类和方法,用于处理字符串、集合、日期等。
mysql-connector-java: 是 MySQL 数据库的 Java 连接器,用于在 Java 应用程序中与 MySQL 数据库进行交互。
druid-spring-boot-starter: 提供了 Druid 数据库连接池的 Spring Boot 集成支持,用于管理和监控数据库连接。
主键手动配置 global-config: db-config: id-type: ASSIGN_ID
解释
在上述配置中,global-config 是 MyBatis-Plus 的全局配置项。其中,db-config 是全局配置项中的数据库配置项。
id-type: ASSIGN_ID 是数据库配置项中的一个属性,用于指定 MyBatis-Plus 的 ID 生成策略为 ASSIGN_ID。这意味着在使用 MyBatis-Plus 进行数据库操作时,主键 ID 的生成策略将采用手动分配方式,即由开发人员在插入数据时手动指定主键的值。
通过设置 id-type: ASSIGN_ID,开发人员可以灵活地控制主键的生成方式,而不是依赖数据库自动生成的方式。这在某些情况下可能很有用,例如当需要在数据插入之前生成唯一的自定义主键时,或者在某些业务逻辑下需要精确地控制主键的取值范围和顺序时。
导入前端文件 注意前端文件的位置,在Boot项目中,前台默认就只能访问resource目录下的static和template文件夹下的文件;所以如果要使用这种方式,直接创建一个static目录就行,然后把这些前端资源放在这个static目录下就行;
实体类和mapper的开发(BaseMapper<Employee>) 在entity导入实体类employee类;
使用mybatis-plus提供的自动生成mapper:
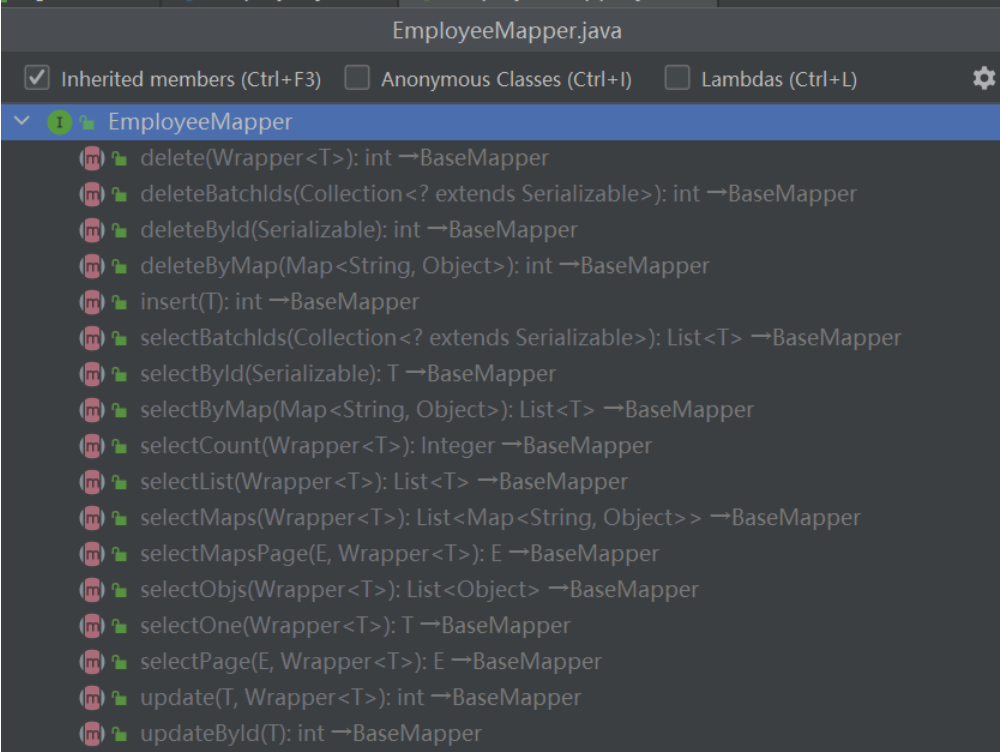
package com.itheima.reggie.mapper; import com.baomidou.mybatisplus.core.mapper.BaseMapper;import com.itheima.reggie.entity.Employee;import org.apache.ibatis.annotations.Mapper; @Mapper public interface EmployeeMapper extends BaseMapper <Employee> {}
该代码片段是一个基于MyBatis-Plus的Mapper接口的示例。 在Java中,Mapper通常用于定义与数据库交互的接口。它提供了一种将数据库操作映射为方法调用的方式,使开发人员可以通过调用Mapper接口的方法来执行数据库的增删改查操作。 在示例中,EmployeeMapper接口继承自BaseMapper<Employee > @Mapper注解用于标识该接口为MyBatis的Mapper接口,这样MyBatis就能够扫描到该接口,并生成对应的实现类。 该EmployeeMapper接口用于操作名为employee的数据表,通过继承BaseMapper<Employee > 开发人员可以根据具体的业务需求,在EmployeeMapper接口中自定义方法,并在方法上添加相应的注解来实现更复杂的数据库操作。
Mapper介绍 在软件开发中,Mapper是一种常见的设计模式,用于将数据存储层与业务逻辑层分离。它负责处理数据存储层(如数据库)与应用程序之间的交互,提供一种将数据从一种表示形式转换为另一种表示形式的机制。 在Java开发中,Mapper通常用于将对象和关系数据库之间进行映射。它的主要作用是将数据库表中的行数据映射到Java对象或将Java对象映射到数据库表中的行数据。 在持久层框架(如MyBatis、Hibernate)中,Mapper通常指的是数据访问对象(DAO)或数据访问层(DAL)。它是一个接口或类,用于定义与数据库交互的方法。
Service package com.itheima.reggie.service;import com.baomidou.mybatisplus.extension.service.IService;import com.itheima.reggie.entity.Employee; public interface EmployeeService extends IService <Employee> { }
package com.itheima.reggie.service.impl; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.itheima.reggie.entity.Employee;import com.itheima.reggie.mapper.EmployeeMapper;import org.springframework.stereotype.Service;@Service public class EmployeeServiceImpl extends ServiceImpl <EmployeeMapper,Employee> implements EmployeeService { }
IService `IService<Employee>` 是一个泛型接口,是 MyBatis-Plus 框架提供的用于定义`服务层` 接口的接口。在这段代码中,`EmployeeService` 接口继承了 `IService<Employee>` 接口,通过泛型参数 `<Employee>` 指定了实体类的类型,即 `Employee` 。 `IService<Employee>` 接口定义了一些常见的数据库操作方法,例如增加、删除、修改、查询等。通过继承 `IService<Employee>` 接口,`EmployeeService` 接口可以直接使用这些数据库操作方法,而无需自己编写具体的实现代码。在 `EmployeeService` 接口中,可以定义自己的业务方法,以及对 `Employee` 实体类的特定操作方法。这些方法可以在 `EmployeeServiceImpl` 类中进行具体的实现。 通过定义 `EmployeeService` 接口,可以在应用程序中进行面向接口的编程,提高代码的可维护性和可扩展性。同时,`EmployeeService` 接口的实现类可以通过依赖注入的方式注入到其他组件中使用。
ServiceImpl<EmployeeMapper,Employee> `ServiceImpl<EmployeeMapper, Employee>` 是 MyBatis-Plus 框架提供的一个通用服务实现类。在这段代码中,`EmployeeServiceImpl` 类继承了 `ServiceImpl<EmployeeMapper, Employee>` ,表示 `EmployeeServiceImpl` 是对 `Employee` 实体类进行数据库操作的服务实现类。`ServiceImpl<EmployeeMapper, Employee>` 是一个泛型类,它接收两个参数:`EmployeeMapper` 和 `Employee` 。`EmployeeMapper` 是 `Employee` 实体类对应的 Mapper 接口,用于执行数据库操作。`Employee` 是实体类的类型,用于指定具体的实体类。通过继承 `ServiceImpl<EmployeeMapper, Employee>` ,`EmployeeServiceImpl` 可以使用 MyBatis-Plus 提供的一些通用方法,如保存实体、根据主键查询实体、更新实体、删除实体等。这些通用方法的实现已经由 MyBatis-Plus 框架提供,无需开发者自己实现。 此外,开发者还可以在 `EmployeeServiceImpl` 类中根据业务需求添加自定义的方法,以实现特定的业务逻辑。通过继承 `ServiceImpl<EmployeeMapper, Employee>` ,`EmployeeServiceImpl` 类可以充分利用 MyBatis-Plus 提供的便捷功能,并扩展自定义的业务逻辑,提高开发效率和代码可维护性。
封装返回的结果类
创建一个新的包,common,用来存放共同使用的类,把这个返回结果类放入这个公共包;
package com.itheima.reggie.common;import lombok.Data;import java.io.Serializable;import java.util.HashMap;import java.util.Map;@Data public class R <T> implements Serializable { private Integer code; private String msg; private T data; private Map map = new HashMap (); public static <T> R<T> success (T object) { R<T> r = new R <T>(); r.data = object; r.code = 1 ; return r; } public static <T> R<T> error (String msg) { R r = new R (); r.msg = msg; r.code = 0 ; return r; } public R<T> add (String key, Object value) { this .map.put(key, value); return this ; } }
细讲 public R<T> add (String key, Object value) { this .map.put(key, value); return this ; }
这里的return this是返回当前对象指针,可以保证能够被链式调用
controller
先处理业务逻辑,然后再编码!!!
1、将页面提交的密码password进行md5加密处理
2、根据页面提交的用户名username查询数据库
3、如果没有查询到则返回登录失败结果
4、密码比对,如果不一致则返回登录失败结果
5、查看员工状态,如果为已禁用状态,则返回员工已禁用结果
6、登录成功,将员工id存入Session并返回登录成功结果
package com.itheima.reggie.controller;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;import com.itheima.reggie.common.R;import com.itheima.reggie.entity.Employee;import com.itheima.reggie.service.EmployeeService;import lombok.extern.slf4j.Slf4j;import org.apache.commons.lang.StringUtils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.util.DigestUtils;import org.springframework.web.bind.annotation.*;import javax.servlet.http.HttpServletRequest;import java.nio.charset.StandardCharsets;import java.time.LocalDateTime;@RestController @Slf4j @RequestMapping("/employee") public class EmployeeController { @Autowired private EmployeeService employeeService; @PostMapping("/login") public R<Employee> login (HttpServletRequest request, @RequestBody Employee employee) { String password = employee.getPassword(); password = DigestUtils.md5DigestAsHex(password.getBytes()); LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(Employee::getUsername, employee.getUsername()); Employee emp = employeeService.getOne(queryWrapper); if (emp == null ) { return R.error("用户不存在" ); } if (!emp.getPassword().equals(password)) { return R.error("密码不正确" ); } if (emp.getStatus() == 0 ) { return R.error("账号已禁用" ); } request.getSession().setAttribute("employee" , emp.getId()); return R.success(emp); } @PostMapping("/logout") public R<String> logout (HttpServletRequest request) { request.getSession().removeAttribute("employee" ); return R.success("退出成功" ); } @PostMapping() public R<String> save (HttpServletRequest request, @RequestBody Employee employee) { employee.setPassword(DigestUtils.md5DigestAsHex("123456" .getBytes())); employeeService.save(employee); return R.success("新增员工成功" ); } @GetMapping("/page") public R<Page> page (int page, int pageSize, String name) { log.info("page = {},pageSize = {},name = {}" , page, pageSize, name); Page pageInfo = new Page (page, pageSize); LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper (); queryWrapper.like(StringUtils.isNotEmpty(name), Employee::getName, name); queryWrapper.orderByDesc(Employee::getUpdateTime); employeeService.page(pageInfo, queryWrapper); return R.success(pageInfo); } @PutMapping public R<String> update (HttpServletRequest request, @RequestBody Employee employee) { log.info(employee.toString()); Long empId = (Long) request.getSession().getAttribute("employee" ); employee.setUpdateTime(LocalDateTime.now()); employee.setUpdateUser(empId); employeeService.updateById(employee); return R.success("员工信息修改成功" ); } @GetMapping("/{id}") public R<Employee> getById (@PathVariable Long id) { Employee employee = employeeService.getById(id); if (employee != null ) { return R.success(employee); } return R.error("没有查询到该员工信息" ); } }
HttpServletRequest request是一个参数,用于获取HTTP请求的相关信息。它是由Spring框架自动注入的,用于处理HTTP请求的头部、参数、Cookie等信息。在这个控制器方法中,HttpServletRequest request被用来存储登录成功后的员工id到Session中。
@RequestBody Employee employee是一个注解和参数的组合,用于将HTTP请求的请求体中的JSON数据映射到Employee对象上。@RequestBody注解告诉Spring MVC框架将请求体中的数据反序列化为Employee对象。在这个控制器方法中,前端传递的JSON数据包含了用户名和密码信息,通过@RequestBody Employee employee将其转换为Employee对象供后续处理。
查询语句 LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(Employee::getUsername, employee.getUsername()); Employee emp = employeeService.getOne(queryWrapper);
304状态码
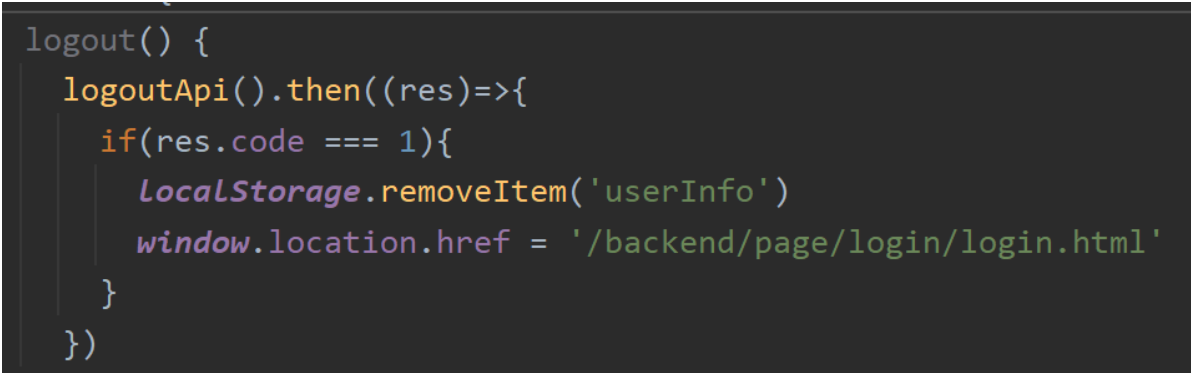
前端的本地存储
localStorage.setItem(‘userInfo’,JSON.stringify(res.data))
后台系统退出功能
后端代码处理:
①在controller中创建对应的处理方法来接受前端的请求,请求方式为post;
②清理session中的用户id
③返回结果(前端页面会进行跳转到登录页面)
@PostMapping("/logout") public R<String> logout (HttpServletRequest request) { request.getSession().removeAttribute("employee" ); return R.success("退出成功" ); }
六、员工管理模块
前面的登陆存在一个问题,如果用户不进行登陆,直接访问系统的首页,照样可以正常访问,这种设计是不合理的,我们希望看到的效果是只有完成了登陆后才可以访问系统中的页面,如果没有登陆则跳转到登陆页面;
答案就是使用过滤器或者是拦截器,在拦截器或者是过滤器中判断用户是否已经完成了登陆,如果没有登陆则跳转到登陆页面;
@WebFilter(filterName = "LongCheckFilter",urlPatterns = "/*") @Slf4j public class LongCheckFilter implements Filter { @Override public void doFilter (ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { HttpServletRequest request = (HttpServletRequest) servletRequest; HttpServletResponse response = (HttpServletResponse) servletResponse; log.info("拦截到的请求:{}" ,request.getRequestURL()); filterChain.doFilter(request,response); } }
路径匹配器 import org.springframework.util.AntPathMatcher;public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher ();把浏览器发过来的请求和我们定义的不拦截的url做比较,匹配则放行 boolean match = PATH_MATCHER.match(url, requestURI);
完善过滤器的处理逻辑
数据响应
response.getWriter().write(JSON.toJSONString(R.error(“NOTLOGIN”)));
这行代码的作用是向客户端发送响应数据。
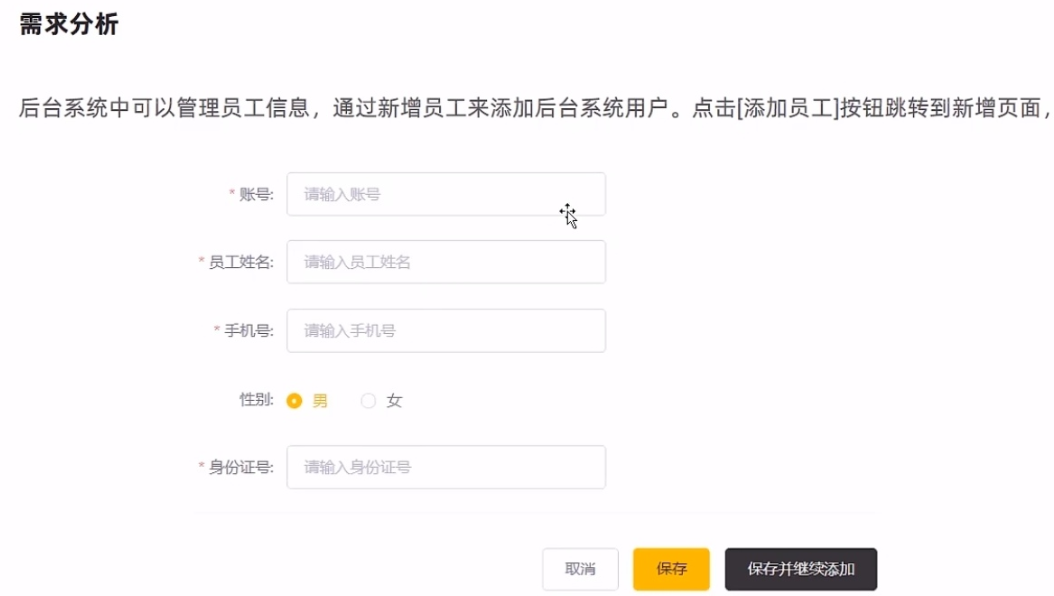
新增员工
@RequestBody
@RequestBody是一个Spring MVC注解,用于指示方法参数应该绑定到请求的主体部分。它可以用于接收请求体中的数据,并将其转换为方法参数所需的对象。
在这段代码中,@RequestBody Employee employee表示将请求体中的数据转换为Employee对象。当前端发送POST请求时,请求体中的JSON数据会被反序列化为Employee对象,并作为方法参数传递给save方法。
通过使用@RequestBody注解,可以方便地将请求体中的数据绑定到方法参数,避免了手动解析请求体和数据转换的繁琐过程。
全局异常捕获 @ControllerAdvice(annotations = {RestController.class, Controller.class}) @ResponseBody @Slf4j public class GlobalExceptionHandler { @ExceptionHandler(SQLIntegrityConstraintViolationException.class) public R<String> exceptionHandle (SQLIntegrityConstraintViolationException exception) { log.error(exception.getMessage()); if (exception.getMessage().contains("Duplicate entry" )){ String[] split = exception.getMessage().split(" " ); String msg = split[2 ] + "这个用户名已经存在" ; return R.error(msg); } return R.error("未知错误" ); }
注解1
@ControllerAdvice(annotations = {RestController.class, Controller.class})
通过@ControllerAdvice注解,我们可以定义一个全局的异常处理器,用于处理应用程序中抛出的异常。在上述代码中,通过annotations属性指定了需要拦截的控制器注解类型,包括@RestController和@Controller。
这段代码是一个全局异常处理器,用于捕获和处理特定类型的异常,并返回对应的错误信息。
以下是代码中的关键部分解释:
@ControllerAdvice(annotations = {RestController.class, Controller.class}): 注解标识该类为全局异常处理器,并指定要拦截的控制器注解类型为RestController和Controller。@ResponseBody: 注解表示方法的返回值将作为响应体返回。@ExceptionHandler(SQLIntegrityConstraintViolationException.class): 注解表示该方法用于处理SQLIntegrityConstraintViolationException类型的异常。public R<String> exceptionHandle(SQLIntegrityConstraintViolationException exception): 方法声明,接收一个SQLIntegrityConstraintViolationException类型的异常作为参数,并返回一个R<String>类型的通用返回结果对象。
在方法实现中,首先通过日志记录异常信息。然后,根据异常信息判断具体的错误类型。如果异常信息中包含”Duplicate entry”,则表示出现了重复插入数据的错误,从异常信息中提取出已存在的用户名,并构造相应的错误信息返回。否则,返回一个默认的未知错误信息。
该全局异常处理器的作用是捕获特定类型的异常并返回对应的错误信息,以提供统一的异常处理机制。
注解2 @ExceptionHandler(SQLIntegrityConstraintViolationException.class)
作用:当发生 SQLIntegrityConstraintViolationException 异常时,全局异常处理器会自动调用被标记的方法来处理该异常。在该方法中,可以根据具体的业务需求进行异常处理逻辑的编写,例如记录日志、返回自定义的错误信息等。@ExceptionHandler 注解,可以将异常处理逻辑集中在一个类中,从而实现全局的异常处理,统一处理项目中出现的特定异常。这样可以提高代码的可维护性和可读性,避免在多个地方重复编写相同的异常处理逻辑。


 微信
微信


