
mysql
常用语法
在 windows 中不区分大小写,在 linux 中区分大小写。
1 基本命令
所有的语句都要以分号结尾
show databases;–查看当前所有的数据库use 数据库名;–打开指定的数据库show tables;–查看所有的表describe/desc 表名;–显示表的信息create database 数据库名;–创建一个数据库exit–退出连接
单行注释:
--或#
多行注释:
/*...*/
2. 操作数据库
2.1 操作数据库
1. 创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名; |
2. 删除数据库
DROP DATABASE [IF EXISTS] 数据库名; |
3. 使用数据库
如果表名或字段名是特殊字符,则需要带``。
use 数据库名; |
4. 查看数据库
SHOW DATABASES; |
2.2 数据库的列类型
数值类型
| 数据类型 | 描述 | 大小 |
|---|---|---|
| tinyint | 十分小的数据 | 1 个字节 |
| smallint | 较小的数据 | 2 个字节 |
| mediumint | 中等大小的数据 | 3 个字节 |
| int | 标准的整数 | 4 个字节 |
| bigint | 较大的数据 | 8 个字节 |
| float | 浮点数 | 4 个字节 |
| double | 浮点数 | 8 个字节 |
| decimal | 字符串形式的浮点数,一般用于金融计算 | 字符串 |
字符串类型
| 数据类型 | 描述 | 大小 |
|---|---|---|
| char | 字符串固定大小 | 0~255 |
| varchar | 可变字符串 | 0~65535 |
| tinytext | 微型文本 | 2^8-1 |
| text | 文本串 | 2^16-1 |
时间日期类型
| 数据类型 | 描述 | 格式 |
|---|---|---|
| date | 日期格式 | YYYY-MM-DD |
| time | 时间格式 | HH: mm: ss |
| datetime | 最常用的时间格式 | YYYY-MM-DD HH: mm: ss |
| timestamp | 时间戳,1970.1.1 到现在的毫秒数 | - |
| year | 年份表示 | - |
特殊类型
null: 没有值,未知,不要用于计算UnSigned: 无符号的,不能为负数ZEROFILL: 0 填充的,不足位数用 0 填充Auto_InCrement: 自增,通常用于设计唯一主键
其他属性
NULL和NOT NULL: 默认为 NULL,如果设置为 NOT NULL,则该列必须有值DEFAULT: 设置默认值
2.3 数据库的字段属性
UnSigned: 无符号的ZEROFILL: 0 填充的Auto_InCrement: 自增NULL和NOT NULL: 默认为 NULLDEFAULT: 默认的
每一个表,都必须存在以下五个字段:
| 名称 | 描述 |
|---|---|
| id | 主键 |
| version | 乐观锁 |
| is_delete | 伪删除 |
| gmt_create | 创建时间 |
| gmt_update | 修改时间 |
2.4 创建数据库表
CREATE TABLE IF NOT EXISTS `student`( |
注意点:
- 表名和字段尽量使用
飘号括起来 AUTO_INCREMENT代表自增- 所有的语句后面加逗号,最后一个不加
- 字符串使用单引号括起来
- 主键的声明一般放在最后,便于查看
- 不设置字符集编码的话,会使用 MySQL 默认的字符集编码 Latin1,不支持中文,可以在 my.ini 里修改
格式:
CREATE TABLE IF NOT EXISTS `表名`( |
常用命令:
SHOW CREATE DATABASE 数据库名;– 查看创建数据库的语句SHOW CREATE TABLE 表名;– 查看表的定义语句DESC 表名;– 显示表的具体结构
2.5 数据库存储引擎
INNODB
- 默认使用,安全性高,支持事务的处理,多表多用户操作
MYISAM
- 早些年使用,节约空间,速度较快
| 功能 | INNODB | MYISAM |
|---|---|---|
| 事务支持 | 支持 | 不支持 |
| 数据行锁定 | 支持 | 不支持 |
| 外键约束 | 支持 | 不支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间大小 | 较大 | 较小 |
数据库文件存在的物理空间位置:
- MySQL 数据表以文件方式存放在磁盘中
- 包括表文件、数据文件、以及数据库的选项文件
- 位置:MySQL 安装目录/data(目录名对应数据库名,该目录下文件名对应数据表)
在 MySQL 中,不同的存储引擎会使用不同类型的文件来存储数据和元数据。下面是 INNODB 和 MYISAM 两种常见存储引擎在文件上的区别:
INNODB
.frm 文件:
- .frm 文件存储了表的结构定义,包括字段名、字段类型、索引等信息。
.ibd 文件:
- .ibd 文件是 INNODB 表的数据文件,它包含了实际的数据,以及与 INNODB 相关的索引和元数据。
ibdata1 文件:
- ibdata1 文件是 INNODB 系统表空间文件,它包含了系统表和共享表空间的数据。在 INNODB 中,数据和索引并不是以单独的文件形式存在,而是存储在共享的表空间中。
MYISAM
.frm 文件:
- .frm 文件同样存储了表的结构定义,包括字段名、字段类型、索引等信息。
.MYD 文件:
- .MYD 文件是 MYISAM 表的数据文件,它包含了表中的实际数据。
.MYI 文件:
- .MYI 文件是 MYISAM 表的索引文件,它包含了 MYISAM 表中的索引数据。
这些文件组成了 MySQL 数据库中不同存储引擎的基本结构。不同存储引擎的文件类型和组织方式会影响数据库的性能、事务支持、并发控制等方面的特性。
2.6 修改数据库
-- 修改表名 |
MySQL 数据管理
外键
# 主表 |
删除有外键关系的表的时候,必须要先删除引用别人的表(从表),再删除被引用的表(主表)
添加 Insert
普通用法
INSERT INTO `student`(`name`) VALUES ('zsr'); |
语法:
INSERT INTO 表名([字段1,字段2..]) VALUES ('值1','值2'..),[('值1','值2'..)..]; |
2. 修改 Update
修改学员名字, 指定条件
UPDATE `student` SET `name`='zsr204' WHERE id=1; |
3. 删除 Delete
DELETE FROM `student`; |
关于 DELETE 删除的问题,重启数据库现象:
- INNODB 自增列会从 1 开始(存在内存当中,断电即失)
- MYISAM 继续从上一个子增量开始(存在磁盘当中,不会丢失)
TRUNCATE
作用: 完全清空一个数据库表,表的结构和索引约束不会变!
- TRUNCATE 用于完全清空一个数据库表,但是表的结构和索引约束不会改变。
- DELETE 可以根据条件删除表中的数据,而 TRUNCATE 只能删除整个表。
- TRUNCATE 重新设置自增列的计数器并将其归零,而 DELETE 不会影响自增列。
- DELETE 是数据操作语言(DML),它将原数据放入回滚段中,可以回滚;而 TRUNCATE 是数据定义语言(DDL),它的操作不会被存储,也不能回滚。
DQL 查询数据
Data Query Language 数据查询语言
SELECT [ALL | DISTINCT] |
-- 创建学校数据库 |
SELECT 字段 FROM 表;
4.1、基础查询
语法:
SELECT 查询列表 FROM 表名; |
查询列表可以是:表中的(一个或多个)字段,常量,变量,表达式,函数。
查询结果是一个虚拟的表格。
查询全部学生:
SELECT * FROM student;
查询指定的字段:
SELECT LoginPwd, StudentName FROM student;
别名 AS(可以给字段起别名,也可以给表起别名):
SELECT StudentNo AS 学号, StudentName AS 学生姓名 FROM student AS 学生表;
函数 CONCAT(str1, str2, …):
SELECT CONCAT('姓名', StudentName) AS 新名字 FROM student;
查询系统版本(函数):
SELECT VERSION();
用来计算(计算表达式):
SELECT 100 * 53 - 90 AS 计算结果;
查询自增步长(变量):
SELECT @@auto_increment_increment;
查询有哪写同学参加了考试,重复数据要去重:
SELECT DISTINCT StudentNo FROM result;
LIKE 运算符支持以下通配符:
%:匹配零个或多个字符。_:匹配任何单个字符。[]:匹配方括号内指定的任何单个字符。[^]:匹配方括号内未指定的任何单个字符。
排序和分页
SELECT 查询列表 |
说明:
ORDER BY子句用于对查询结果进行排序。ASC表示升序(从最小到最大)。DESC表示降序(从最大到最小)。ORDER BY的位置一般放在查询语句的最后(除LIMIT语句之外)。
SELECT `StudentNo`, `StudentName`, `GradeName` |
该查询将按 StudentNo 列降序排列结果。
SELECT 查询列表 |
说明:
LIMIT子句用于对查询结果进行分页。offset代表起始的条目索引(默认从 0 开始)。pagesize代表显示的条目数。offset = (n-1) * pagesize,其中n为当前页面。
示例:
- 第一页:
LIMIT 0, 5 - 第二页:
LIMIT 5, 5 - 第三页:
LIMIT 10,5 - 第 n 页:
LIMIT (n-1) * pagesize, pagesize
计算总页数:
总页数 = 数据总数 / 页面大小
函数
| 函数 | 作用 |
|---|---|
ABS(-8) |
返回绝对值 |
CEIL(5.1) |
向上取整 |
CEILING(5.1) |
向上取整 |
RAND() |
返回 0 到 1 之间的一个随机数 |
SIGN(-10) |
返回一个数的符号;0 返回 0,正数返回 1,负数返回 -1 |
CHAR_LENGTH('我喜欢你') |
返回字符串的长度 |
CONCAT('我','喜欢','你') |
拼接字符串 |
INSERT('我喜欢',1,1,'超级') |
从字符串的指定位置开始替换为指定长度的新字符串 |
UPPER('zsr') |
将字符串转换为大写 |
LOWER('ZSR') |
将字符串转换为小写 |
INSTR('zsrs','s') |
返回第一次出现指定子字符串的索引位置 |
REPLACE('加油就能胜利','加油','坚持') |
替换字符串中出现的指定子字符串 |
SUBSTR('坚持就是胜利',3,6) |
返回指定位置开始的指定长度的子字符串 |
REVERSE('rsz') |
反转字符串 |
CURRENT_DATE() |
获取当前日期 |
CURDATE() |
获取当前日期 |
NOW() |
获取当前时间 |
LOCALTIME() |
获取本地时间 |
SYSDATE() |
获取系统时间 |
YEAR(NOW()) |
获取当前年份 |
MONTH(NOW()) |
获取当前月份 |
DAY(NOW()) |
获取当前日 |
HOUR(NOW()) |
获取当前小时 |
MINUTE(NOW()) |
获取当前分钟 |
SECOND(NOW()) |
获取当前秒 |
SYSTEM_USER() |
获取当前登录的系统用户 |
USER() |
获取当前登录的数据库用户 |
VERSION() |
获取 MySQL 的版本信息 |
加密
CREATE TABLE testMD5( |
事务原则:ACID
| 名称 | 描述 |
|---|---|
| 原子性 | 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 |
| 一致性 | 事务前后数据的完整性必须保持一致。 |
| 隔离性 | 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 |
| 持久性 | 事务一旦被提交则不可逆,被持久化到数据库中,接下来即使数据库发生故障也不应该对其有任何影响。 |
事务并发导致的问题
| 名称 | 描述 |
|---|---|
| 脏读 | 指一个事务读取了另外一个事务未提交的数据。 |
| 不可重复读 | 在一个事务内读取表中的某一行数据,多次读取结果不同。 |
| 虚读(幻读) | 是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。 |
隔离级别
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 是 | 是 | 是 |
| 读已提交 | 否 | 是 | 是 |
| 可重复读 | 否 | 否 | 是 |
| 串行化 | 否 | 否 | 否 |
执行事务的过程
关闭自动提交:
SET autocommit=0;
事务开启:
START TRANSACTION -- 标记一个事务的开始,从这个之后的 SQL 都在同一个事务内
成功则提交,失败则回滚:
提交:持久化(成功)
COMMIT
回滚:回到原来的状态(失败)
ROLLBACK
事务结束:
SET autocommit=1; -- 开启自动提交
其他操作:
保存点:
SAVEPOINT 保存点名; -- 设置一个事务的保存点
ROLLBACK TO SAVEPOINT 保存点名; -- 回滚到保存点
RELEASE SAVEPOINT 保存点名; -- 撤销保存点
7、索引
索引(Index)是帮助 MySQL 高效获取数据的数据结构。
- 提高查询速度
- 确保数据的唯一性
- 可以加速表和表之间的连接,实现表与表之间的参照完整性
- 使用分组和排序子句进行数据检索时,可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化
7.1、索引的分类
-- 创建学生表 student |
主键索引(PRIMARY KEY)
主键索引是唯一的标识,主键不可重复,只有一个列作为主键。它是最常见的索引类型,不允许为空值,用于确保数据记录的唯一性,确定特定数据记录在数据库中的位置。
-- 创建表的时候指定主键索引
CREATE TABLE tableName (
…
PRIMARY INDEX (columnName)
)
-- 修改表结构添加主键索引
ALTER TABLE tableName ADD PRIMARY INDEX (columnName)普通索引(KEY / INDEX)
普通索引是最默认的索引类型,用于快速定位特定数据。应该添加在查询条件的字段上。
-- 直接创建普通索引
CREATE INDEX indexName ON tableName (columnName)
-- 创建表的时候指定普通索引
CREATE TABLE tableName (
…
INDEX [indexName] (columnName)
)
-- 修改表结构添加普通索引
ALTER TABLE tableName ADD INDEX indexName(columnName)唯一索引(UNIQUE KEY)
唯一索引与普通索引类似,但索引列的值必须唯一,允许有空值。与主键索引的区别在于,主键索引只能有一个,而唯一索引可以有多个。
-- 直接创建唯一索引
CREATE UNIQUE INDEX indexName ON tableName(columnName)
-- 创建表的时候指定唯一索引
CREATE TABLE tableName(
…...
UNIQUE INDEX [indexName] (columnName)
);
-- 修改表结构添加唯一索引
ALTER TABLE tableName ADD UNIQUE INDEX [indexName] (columnName)全文索引(FULLTEXT)
全文索引是一种用于快速定位特定数据的索引类型,通常用于大型数据集和全文搜索。
-- 增加一个全文索引
ALTER TABLE student ADD FULLTEXT INDEX StudentName(StudentName);使用
EXPLAIN分析 SQL 执行的情况:非全文索引:
EXPLAIN SELECT * FROM student;
全文索引:
EXPLAIN SELECT * FROM student WHERE MATCH(StudentName) AGAINST('d');
# 数据库引擎会使用StudentName列上的全文索引来快速搜索包含'd'的记录。
三大范式
- 第一范式(1NF):所有字段值都是不可分解的原子值。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,
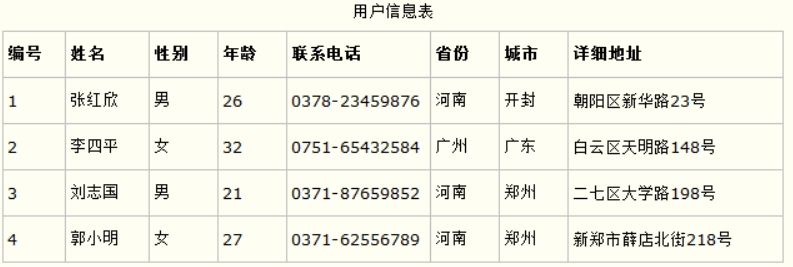
第二范式(2NF):
也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键。
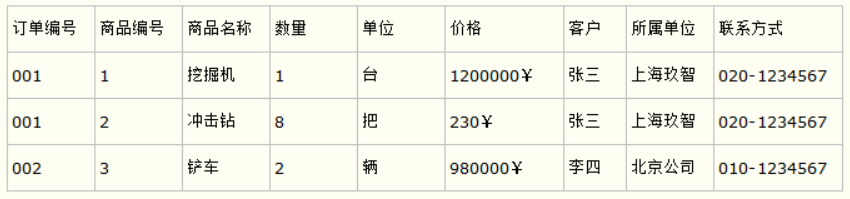
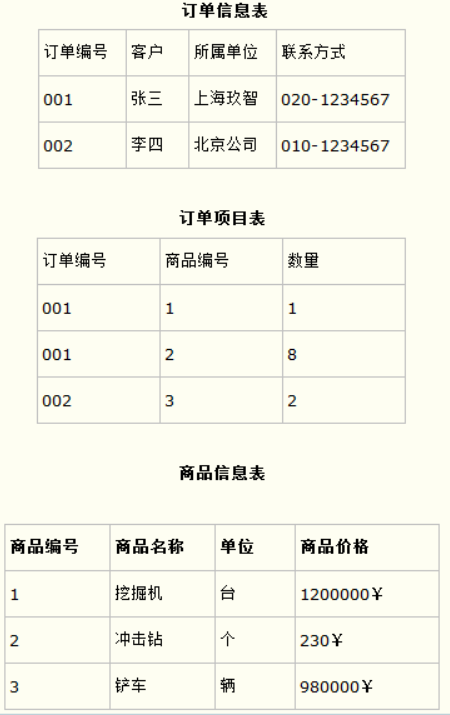
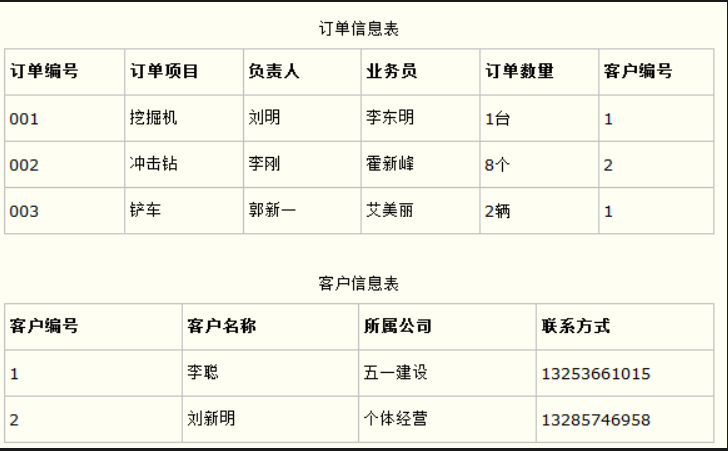
- 第三范式(3NF):
每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
直接操作流程
这是一个创建名为 tb_user 的表的 DDL 语句,其中包含了表的结构和约束。以下是对该 DDL 语句的解释:
create table tb_user |
解释:
create table tb_user:创建名为tb_user的表。user_id:定义一个名为user_id的字段,类型为bigint,并且具有自增特性,作为主键。username:定义一个名为username的字段,类型为varchar(50),不能为空,用于存储用户名。mobile:定义一个名为mobile的字段,类型为varchar(20),不能为空,用于存储手机号。password:定义一个名为password的字段,类型为varchar(64),可以为空,用于存储密码。create_time:定义一个名为create_time的字段,类型为datetime,可以为空,用于存储创建时间。constraint index_tb_user_username unique (username):创建一个名为index_tb_user_username的唯一索引,用于确保username的唯一性。constraint username unique (username):创建一个名为username的唯一约束,也是为了确保username的唯一性。comment '用户':给表添加注释,描述为“用户”。
该 DDL 语句创建了一个名为 tb_user 的表,包含了主键、唯一索引和唯一约束等约束,以及对各个字段的数据类型和注释进行定义。
主从复制
主从复制的原理
主从复制主要用于备份和提高读取性能。在主从复制中,有一个主服务器(Master)和一个或多个从服务器(Slave)。
- 主服务器:主服务器处理写操作(INSERT, UPDATE, DELETE 等)。每当主服务器完成一个写操作,它都会在其二进制日志(Binary Log)中记录下这个操作。
- 二进制日志是一个记录主服务器所有写操作的日志文件,每个事件(写操作)在二进制日志中都有一个唯一的位置。
- 从服务器:从服务器开始时会从主服务器复制其整个数据集(这个过程叫做快照)。之后,从服务器将持续读取主服务器的二进制日志,并在本地应用这些日志中的写操作,从而保持与主服务器的数据同步。
- 从服务器也可以配置成定期从主服务器取得二进制日志的更新。
使用
准备好 2 台服务器
实现主从复制的步骤大致如下:
在主库上操作:
首先,你需要在主库中打开二进制日志(binary log),这是 MySQL 的一种日志文件,用于记录数据的修改情况。你可以在 MySQL 配置文件(如my.ini)中添加或修改以下配置:[mysqld]
log-bin=mysql-bin # 开启二进制日志
server-id=1 # 设置 server-id,主库和从库的 server-id 必须不同然后重启 MySQL 服务以应用配置更改。
接着,你需要创建一个用于主从复制的用户,并给予该用户复制的权限。假设你想创建的用户名为
repl,密码为password,可以运行以下 SQL 命令:GRANT REPLICATION SLAVE ON . TO 'repl'@'%' IDENTIFIED BY 'password';
最后,你需要获取当前的二进制日志文件名和位置,可以通过运行
SHOW MASTER STATUS;命令获得。这些信息在接下来设置从库的时候需要用到。在从库上操作:
同样的,你需要在 MySQL 配置文件中添加或修改以下配置:[mysqld]
server-id=2 # 设置 server-id,主库和从库的 server-id 必须不同然后重启 MySQL 服务以应用配置更改。
接着,你需要配置从库连接到主库,并开始复制。这里假设主库的 IP 地址为
192.168.1.100,二进制日志文件名为mysql-bin.000001,位置为120,可以运行以下 SQL 命令:CHANGE MASTER TO
MASTER_HOST='192.168.1.100',
MASTER_USER='repl',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=120;最后,启动复制过程,运行以下 SQL 命令:
START SLAVE;
说明
写(增删改)操作在 master 库中,比如: update xxx set status = xxx
读(查询)操作在 slave 库中, 比如: select from xxx
Sharding-jdbc 增强版 JDBC
配置读写分离规则
spring: |
基础学习
# 创建数据库 |
docker 配置 Mysql
# 1.找镜像 |
| 数据类型 | 说明 |
|---|---|
| VARCHAR(50) | VARCHAR 代表可变长度的字符类型,允许存储不超过指定长度的字符数据。 |
| PRIMARY KEY (SNO, PNO, JNO) | PRIMARY KEY (SNO, PNO, JNO) 定义了一个复合主键,由三个字段组成:SNO, PNO, 和 JNO。这意味着这三个字段的组合必须唯一地标识表中的每一行,并且可以用来唯一地标识表中的每个记录。 |
| FOREIGN KEY (SNO) REFERENCES S(SNO) | FOREIGN KEY (SNO) REFERENCES S(SNO) 定义了一个外键约束。当前表中的 SNO 列的值必须是表 S 中已经存在的 SNO 列的值之一,否则将会违反外键约束。 |
| JNO VARCHAR(10) | JNO VARCHAR(10) PRIMARY KEY 这意味着 JNO 列将包含最大长度为 10 的字符串,并且这个列的值将唯一标识表中的每一行。主键约束确保表中的每条记录都具有唯一的 JNO 值,且不允许该列包含空值或重复值。 |
 微信
微信- 支付宝



