
面试高频考点
前言
根据一个大佬的收集整理而来
对JVM的理解(8-24)
JDK包括什么
Java Development Kit (JDK) 是用于开发和编译 Java 应用程序的软件包。
- 编译器(javac): 它将 Java 源代码编译成 Java 字节码,这是 Java 虚拟机(JVM)可以理解和执行的中间代码。
- 运行时环境(JRE): JRE 包括了 JVM 以及 Java 标准库,允许你运行已编译的 Java 程序。
JVM包括什么
主要分为下面五个部分:
- 类加载器(Class Loader):加载字节码文件到内存。
- 运行时数据区(Runtime Data Area):JVM 核心内存空间结构模型。
- 执行引擎(Execution Engine):对 JVM 指令进行解析,翻译成机器码,解析完成后提交到操作系统中。
- 本地库接口(Native Interface):供 Java 调用的融合了不同开发语言的原生库。
- 本地方法库(Native Libraies):Java 本地方法的具体实现。
这其中最复杂的是运行时数据区,它也是 JVM 内存结构最重要的部分。运行时数据区又可以分为方法区、虚拟机栈、本地方法栈、堆以及程序计数器,并且方法区和堆是线程共享的,虚拟机栈、本地方法栈、程序计数器是线程隔离的。下面详细讲解运行时数据区的各个组成部分。
方法区
方法区存储虚拟机加载的类信息、常量、静态变量以及即时编译器编译后的代码等数据。方法区是一种规范,它的其中一种实现是永久代。JDK 7 以前的版本字符串常量池是放在永久代中的,JDK 7 将字符串常量池移动到了堆中,JDK 8 直接删除了永久代,改用元空间替代永久代。
本地方法栈
本地方法栈与 Java 栈的作用和原理基本相同,都可以用来执行方法,不同点在于 Java 栈执行的是 Java 方法,本地方法栈执行的是本地方法。
程序计数器
程序计数器占用的内存空间较小,是当前线程所执行的字节码行号指示器,通过改变这个计数器的值来选取下一条需要执行的字节码指令。多个线程之间的程序计数器相互独立,为了保证每个线程恢复后都可以找到具体的执行位置。
Java 堆
Java 堆用来存放实例化对象,它被所有线程共享,在虚拟机启动时创建,用来存放对象实例,其占用了 Java 内存的大部分空间,是 GC 的主要管理区域,又可分为年轻代、老年代、永久代。
虚拟机栈
Java 栈中存放的是多个栈帧,每个栈帧对应一个被调用的方法,主要包括局部变量表、操作数栈、动态链接、方法返回地址(方法出口)。每一个方法的执行,JVM 都会创建一个栈帧,并且将栈帧压入 Java 栈,方法执行完毕,该栈帧出栈。也就是说,每个方法的执行都是一个栈帧的入栈和出栈过程,Java 虚拟机栈用来存储栈帧,方法调用结束之后,帧会被销毁。
为什么编译成字节码
跨平台性(平台无关性): Java 字节码具有跨平台性,也就是说,一旦将源代码编译成字节码,它就可以在任何支持 Java 虚拟机(JVM)的平台上运行,而不需要重新编译。这使得 Java 成为一种具有很高可移植性的编程语言。
动态执行: Java 字节码由 JVM 解释和执行。这意味着字节码可以在运行时动态加载和执行,而不需要在编译时确定所有细节。这种灵活性使得 Java 支持许多动态特性,如反射、动态代理等。
面向对象、面向过程
面向对象:
考虑一个图书馆管理系统,其中有图书、读者和图书管理员。在面向对象编程中,我们可以创建三个类:Book(图书类)、Reader(读者类)和Librarian(图书管理员类)。每个类都有自己的属性和方法。例如,Book 类可以有属性如书名、作者、出版日期等,以及方法如借阅和归还。通过创建这些类,我们可以创建图书对象、读者对象和图书管理员对象,并通过它们的交互来模拟图书馆管理系统。
面向过程:
考虑一个简单的计算器程序,它可以执行加法、减法、乘法和除法操作。在面向过程编程中,我们可以编写不同的函数来执行每个操作,例如 add(a, b)、subtract(a, b)、multiply(a, b) 和 divide(a, b)。然后,我们可以按照需要调用这些函数,以便完成计算器的功能。
面向对象编程将程序组织为对象的集合,强调对象之间的关系和交互。而面向过程编程将程序组织为一系列的步骤或过程,强调问题解决的步骤和顺序。
内存溢出和内存泄漏的区别(8-28)
内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。
内存泄露 memory leak,是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
内存泄漏是指你向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete),结果你申请到的那块内存你自己也不能再访问(也许你把它的地址给弄丢了),而系统也不能再次将它分配给需要的程序。
- 常发性内存泄漏。发生内存泄漏的代码会被多次执行到,
每执行一次都会导致一块内存泄漏。 - 偶发性内存泄漏。发生内存泄漏的代码只有
在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。 - 一次性内存泄漏。
发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。 - 隐式内存泄漏。
程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
自己的理解:溢出:空间不足。泄露:不去释放。
JDK1.7和JDK1.8的内存模型比较
java一日游
Hello World 是如何运行的
链接推荐
CAS
一种无锁算法,用于实现多线程环境下的原子操作
可能会有CPU空转情况,解决方法是:自适应自旋锁。
普通自旋锁是一直进行忙等待,自适应自旋锁是先空转到一定次数后,进行阻塞等待。
线程池
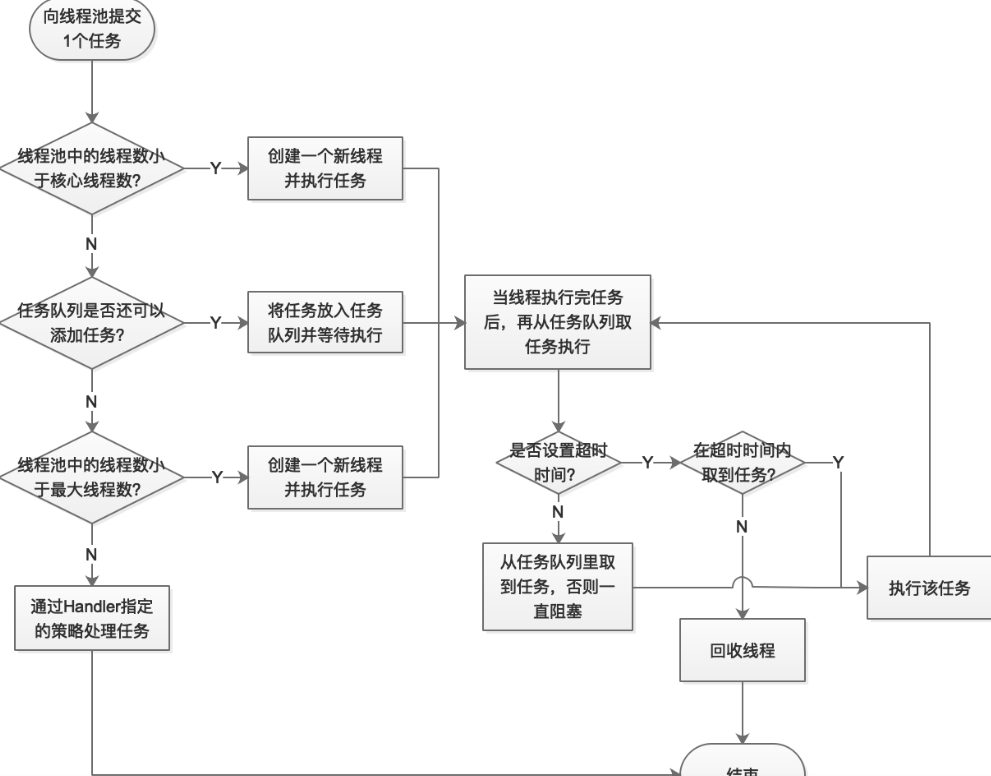
隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 无 | 可能 | 可能 |
| 可重复读 | 无 | 无 | 可能 |
| 串行化 | 无 | 无 | 无 |
- 脏读(Dirty Read): 一个事务读取到另一个事务未提交的数据。
- 不可重复读(Non-Repeatable Read): 在同一事务中,两次读取到的数据不一致,通常是由于其他事务的更新导致的。
- 幻读(Phantom Read): 在同一事务中,两次查询的结果集不一致,通常是由于其他事务的插入或删除导致的。
Redis
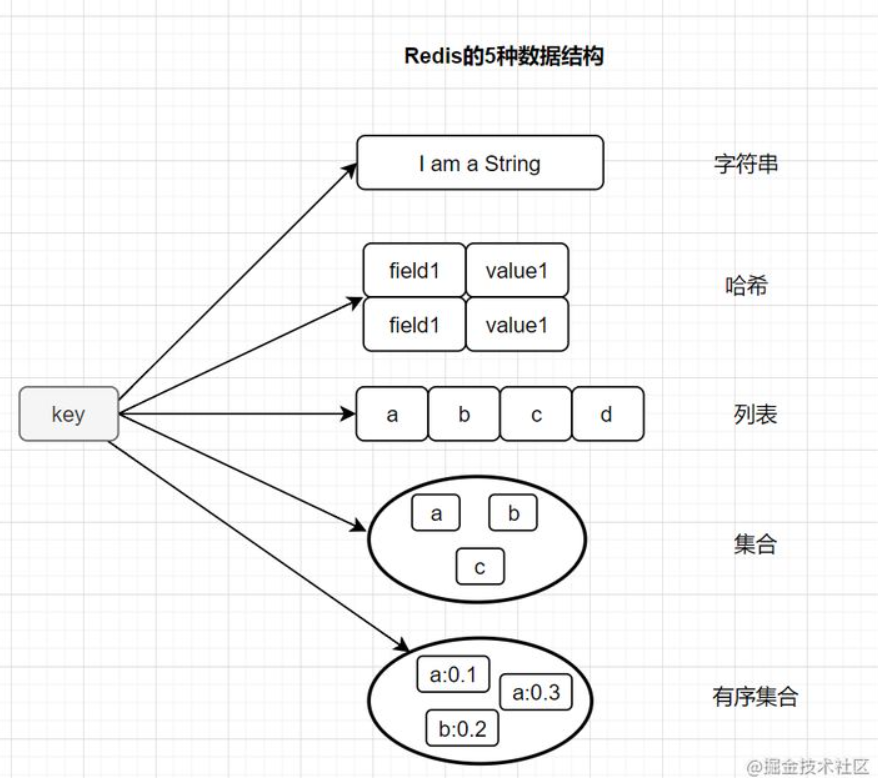
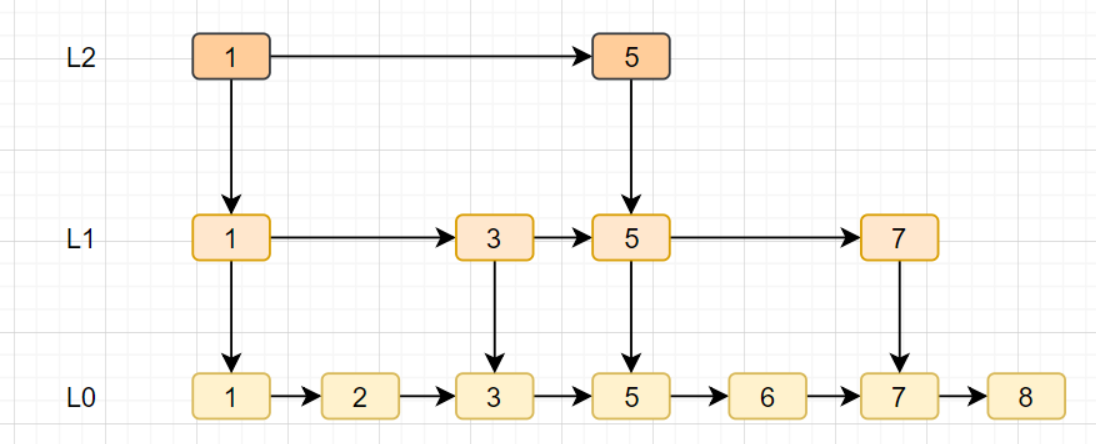
跳表
MySQL索引
在 MySQL 中,索引是一种用于提高数据库查询性能的数据结构。它类似于书籍的目录,允许数据库系统快速地定位并访问特定行的数据,而不必扫描整个表。通过使用索引,可以显著加速数据的检索和查询操作。
主键索引(Primary Key Index): 主键是一列或一组列,其值用于唯一标识表中的每一行。MySQL 自动为主键创建索引,确保表中的每一行都可以快速被唯一标识。
CREATE TABLE example_table (
id INT PRIMARY KEY,
name VARCHAR(255)
);唯一索引(Unique Index): 类似于主键索引,但允许有空值,确保列中的值在整个表中是唯一的。
CREATE TABLE example_table (
email VARCHAR(255) UNIQUE,
name VARCHAR(255)
);普通索引(Normal Index): 基本的索引类型,用于加速检索操作。
CREATE TABLE example_table (
age INT,
INDEX idx_age (age)
);全文索引(Full-Text Index): 用于全文搜索,通常在包含文本数据的列上创建,以提高搜索效率。
CREATE TABLE example_table (
text_column TEXT,
FULLTEXT INDEX idx_text (text_column)
);
死锁
- 破坏互斥条件:把只能互斥使用的资源改成允许共享使用的资源,例如spooLing技术,将独占设备在逻辑上改造成共享设备
- 破坏不可剥夺条件:当某个进程请求新资源无法得到满足时,就立即释放保持的所有资源,待以后需要再重新申请
- 破坏请求和保持条件:非阻塞加锁,加不上锁则释放已有的锁。采用静态分配方法,即进程在运行前一次申请完它所需要的的资源,在它资源未满足前,不让他运行,一旦运行,这些资源都归它所有,此时不会在请求其他资源
- 破坏循环等待条件:保证加锁解锁顺序一致。采用顺序资源分配法,首先给系统中的资源进行编号,规定进程必须按编号递增的顺序请求资源。例如一个进程只有已占有小编号资源时,才可以申请更大编号的资源
双亲委派机制


Map
在Java中,HashMap、TreeMap和LinkedHashMap是Map接口的不同实现,它们之间有一些关键的差异,主要涉及到存储顺序、性能特征和适用场景。
1. HashMap
存储顺序:
HashMap不保证存储顺序,元素的存储顺序是由键的哈希码(hashCode)决定的。性能特征:
HashMap具有良好的性能,常数时间复杂度的查找、插入和删除操作。适用场景: 适用于大多数情况,不要求有序性,对性能要求较高。
2. TreeMap
存储顺序:
TreeMap会对键进行排序,可以按照键的自然顺序或者通过自定义比较器进行排序。性能特征:
TreeMap的性能相对较差,因为它维护了一棵红黑树,查找、插入和删除的时间复杂度为对数级别。适用场景: 适用于需要有序键值对的情况,对有序性要求较高。
3. LinkedHashMap
存储顺序:
LinkedHashMap会保留元素插入的顺序,即按照元素插入的顺序来维护键值对的顺序。性能特征:
LinkedHashMap的性能较好,查找、插入和删除的时间复杂度为常数级别,略低于HashMap。适用场景: 适用于需要有序性,且希望保留元素插入顺序的情况。
总结
- 使用
HashMap适用于大多数情况,无序性、性能要求较高。 - 使用
TreeMap适用于需要有序键值对,对有序性要求较高的情况。 - 使用
LinkedHashMap适用于需要有序性,且希望保留元素插入顺序的情况,性能介于HashMap和TreeMap之间。
JVM
java内存模型

详解


synchronized、volatile 、 Lock
synchronized、volatile 和 Lock 都是 Java 中用于处理多线程同步的机制,但它们在实现方式、应用场景和使用方法上有一些区别。
1. synchronized(同步方法、同步块)
实现方式:
synchronized 是 Java 中最基本的同步机制,可以用于方法和代码块。它依赖于对象的内部锁(Intrinsic Lock)或者称为监视器锁(Monitor Lock)。
区别与注意事项:
synchronized依赖于对象锁,当线程获得锁时,其他线程会被阻塞。- 一个线程在执行同步代码块时,其他线程不能执行相同对象的其他同步代码块,但可以执行该对象的非同步代码块。
2. volatile
实现方式:
volatile 是一种轻量级的同步机制,它保证了变量的可见性和禁止指令重排序。
区别与注意事项:
volatile用于保证多个线程能够正确处理共享变量。- 它不具备原子性,不适合替代
synchronized来进行复合操作。
3. Lock(ReentrantLock)
实现方式:
Lock 是 Java 中的显式锁,它提供了更灵活的线程同步方式,支持可重入锁。
区别与注意事项:
Lock提供了更灵活的同步控制,支持公平锁和非公平锁。- 在使用
Lock时,需要手动释放锁,通常使用try-finally块确保锁的释放。
应用场景:
- 使用
synchronized适用于简单的同步需求,例如方法或代码块的同步。 - 使用
volatile适用于变量的简单读写操作,且变量的值不依赖于当前值。 - 使用
Lock适用于需要更灵活控制的场景,例如支持公平性、锁的中断等。
在实际应用中,选择合适的同步机制取决于具体的需求和性能考虑。一般情况下,推荐使用 synchronized 和 volatile,而在更复杂的情况下,可以考虑使用 Lock。
创建线程
1. 继承 Thread 类:
class MyThread extends Thread { |
2. 实现 Runnable 接口:
class MyRunnable implements Runnable { |
3. 使用匿名内部类:
Runnable myRunnable = new Runnable() { |
4. 使用 Callable 和 Future:
import java.util.concurrent.Callable; |
5. 使用线程池:
import java.util.concurrent.ExecutorService; |
Get与Post
1. 数据传递方式:
GET:
- 数据附在 URL 后面,以查询字符串的形式传递。
- 有长度限制,由浏览器和服务器的限制决定,一般在 2KB 到 8KB 之间。
- 数据在 URL 中可见,安全性较低。
- 适用于无副作用的幂等请求,比如搜索。
http://example.com/path?param1=value1¶m2=value2
POST:
- 数据附在请求体中,对应于 HTTP 报文的消息体。
- 没有明确长度限制,由服务器和客户端的配置决定,通常支持较大的数据传输。
- 数据不在 URL 中可见,安全性相对较高。
- 适用于有副作用的请求,比如表单提交。
2. 安全性:
GET:
- 因为数据附在 URL 中,对于敏感信息不够安全,例如密码。
- 浏览器会缓存发送过的 URL,因此可能会被浏览器历史记录、代理服务器等记录。
POST:
- 数据在请求体中,相对安全,适用于传输敏感信息。
- 不会被浏览器缓存。
3. 幂等性:
GET:
- 幂等,多次执行不会产生不同的结果,不会改变服务器状态。
POST:
- 不一定幂等,因为可能引起服务器状态的改变,比如向数据库插入数据。
4. 可见性:
GET:
- 数据在 URL 中可见,适合用于传递非敏感信息。
POST:
- 数据在请求体中,相对安全,适用于传递敏感信息。
5. 缓存:
GET:
- 可以被浏览器缓存,可以被书签保存。
POST:
- 一般不被浏览器缓存,不适合保存为书签。
6. 使用场景:
GET:
- 用于请求数据,对服务器没有副作用。
- 用于 idempotent 操作。
POST:
- 用于提交表单数据,上传文件等可能引起服务器状态改变的操作。
- 不一定要求 idempotent 操作。
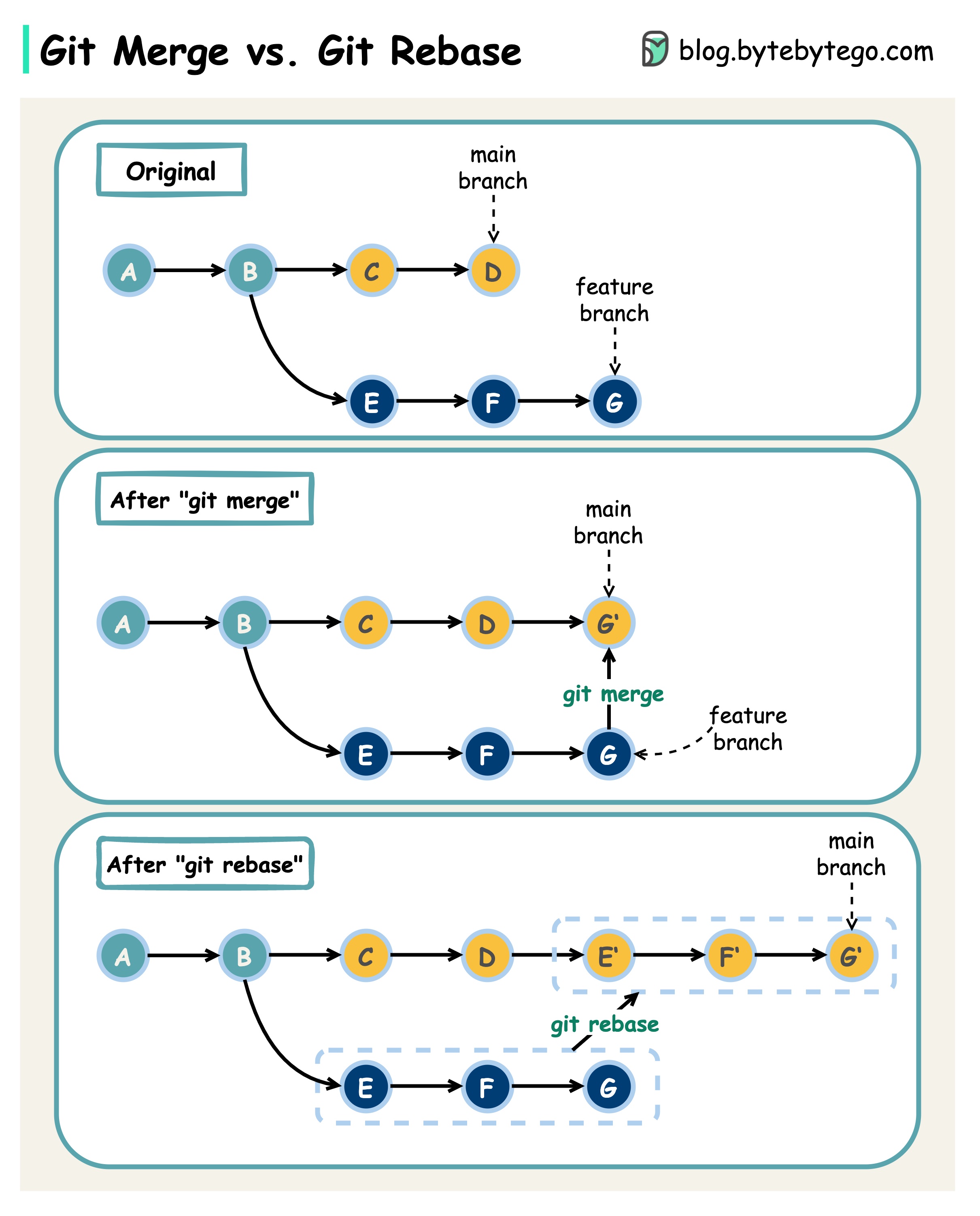
Git merge vs. Git rebase
What are the differences?
手写LRU
题目描述
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。
最近用过的放在前边,放不下了删后边。(get put操作都算用过)
|
Java面试题复习总结(自用)
多线程
线程池:
- 为什么使用线程池?
- 说一下创建线程池时的核心参数和线程池执行原理?
- 线程池的拒绝策略有哪些?
- 常用的阻塞队列有哪些?
- ArrayBlockingQueue和LinkedBlockingQueue的区别?
- 阻塞队列的作用?
- 为什么不先创建救急线程而是先把任务添加到阻塞队列中?
- 具体说说常见的线程池种类?
- 如何确定核心线程数和最大线程数?
线程基础:
- 线程与进程的区别是什么?
- 谈一谈守护线程?
- 创建线程的方式有哪些?
- 实现Callable接口和Runnable接口都可以创建线程,二者的区别是什么?
- 线程的start()和run()方法的区别?
- 线程有哪些状态,这些状态之间是如何切换的?
- wait()、sleep()、yield()和join()方法之间的区别?
- notify()和notifyAll()方法的对比?
- 如何保证多个线程之间的执行顺序?
- 如何终止一个正在运行中的线程?
- ThreadLocal的实现原理?
- ThreadLocal是如何导致内存泄漏的?
- 如何防止ThreadLocal内存泄漏?
并发安全:
- 讲一下Java内存模型?
- 谈谈你对线程安全问题的理解?
- Java是如何保证多线程的执行安全?
- Synchronized关键字的底层原理?
- 锁机制是如何升级的?
- Synchronized和Lock的区别?
- 谈一谈你对volatile关键字的理解?
- Synchronized和volatile关键字的区别?
- 谈一谈AQS?
- 了解CAS吗?
- 讲一下乐观锁和悲观锁?
- ReentranLock的实现原理是什么?
- ReentranLock和Synchronized的区别?
- 聊一下ConcurrentHashMap?
Spring
- 什么是Spring框架?
- Spring框架的优势是什么?
- Spring框架中用到了哪些设计模式?
- 解释一下Bean的生命周期?
- BeanFactory和ApplicationContext的区别?
- 解释一下Spring支持的几种Bean的作用域?
- Spring框架中的单例Bean是线程安全的吗?
- 什么是Bean的自动装配?有哪些方式?
- 解释Spring中的循环引用?
- 构造函数中的循环依赖怎么解决?
- 谈谈你对IOC的理解?
- 如何实现一个IOC容器?
- 什么是AOP?
- Spring中事务是如何实现的?
- 声明式事务的原理是什么?
- Spring中事务的隔离级别?
- Spring中事务的传播机制?
- Spring中事务失效的场景有哪些?解决方法?
- @Autowired和@Resource的区别?
SpringMVC
- SpringMVC的执行流程了解吗?
SpringBoot
- Spring、SpringMVC、SpringBoot有什么区别?
- 如何理解SpringBoot中的starter?
- 讲一讲SpringBoot中的自动配置?
MyBatis
- MyBatis是什么?
- MyBatis框架的优缺点?
- ORM是什么?
- #{}和${}的区别是什么?
- MyBatis执行流程/工作原理是什么?
- MyBatis是否支持延迟加载?
- 延迟加载的底层原理是什么?
- MyBatis的一级、二级缓存使用过吗?
- 二级缓存什么时候会清理缓存中的数据?
MySQL
事务:
- 介绍一下事务的四大特性?
- 并发事务会带来哪些问题?
- 如何解决并发事务带来的问题/事务的隔离级别有哪些?
- 可重复读和幻读的区别?
- 事务的ACID靠什么保证?
- 事务的三大日志是什么?作用?
- bin log 和 redo log的区别?
- undo log 和 redo log的区别?
- 什么是MVCC?实现原理是什么?
优化:
其它:
- MySQL主从同步是如何实现的?
1.什么是缓存,它在高并发系统中起什么作用?
缓存是一种硬件或软件的组件,它存储数据,以便在将来的请求中,如果同样的数据被请求,可以更快地提供数据。在高并发系统中,缓存可以显著提高数据读取的速度,减少对原始数据源(例如数据库)的访问,从而降低系统的响应时间,并提高系统的吞吐量。对于高访问频率和相对静态的数据,将其存储在缓存中可以减少对后端服务器的负载,提高系统的性能和可伸缩性。同时,缓存也可以作为一种缓冲机制,帮助系统应对突然的流量峰值,防止后端服务器被过载。
2.如何选择适合高并发场景的缓存策略?
选择适合高并发场景的缓存策略通常需要考虑以下几个因素:
- 数据的访问模式: 如果数据的访问模式是读多写少,且数据更新不频繁,那么使用缓存可以大幅度提高系统的性能。如果数据更新非常频繁,那么缓存的效果可能就不明显。
- 数据的一致性需求: 如果系统对数据的一致性要求非常高,需要考虑如何在更新原始数据的同时更新缓存,以保证数据的一致性。
- 缓存的大小和数据的大小: 缓存的大小必须足够大,以便存储高访问频率的数据。同时,需要考虑数据的大小,如果单个数据项非常大,那么可能需要使用特殊的缓存策略,如对象缓存。
- 缓存的失效策略: 常见的缓存失效策略有LRU(最近最少使用)、FIFO(先进先出)等。选择何种失效策略取决于具体的数据访问模式。
- 分布式缓存: 对于大规模的高并发系统,可能需要使用分布式缓存,如Redis或Memcached,以提高系统的可扩展性。
3.如何解决缓存系统中的热点数据问题?
“热点数据”是指在一段时间内被频繁访问的数据。在高并发环境下,大量请求同时访问热点数据可能会导致缓存服务器的压力增大,甚至可能导致缓存服务的瘫痪。以下是一些解决策略:
- 缓存预热: 在系统启动时,主动将可能成为热点的数据加载到缓存中,这样可以避免大量请求同时对数据库发起查询。
- 数据复制: 对于热点数据,可以在缓存层面进行数据复制,即将热点数据复制到多个缓存节点中,分散访问压力。
- 一致性哈希: 通过一致性哈希算法,可以将请求均匀地分散到多个缓存节点上,减轻单个节点的压力。
- 限流: 对于访问特别频繁的热点数据,可以通过限流控制请求的频率,保证系统的稳定性。
- 熔断降级: 设定系统的阈值,当访问量或者错误率超过一定的阈值时,启动熔断机制,暂时停止服务,或者提供降级服务,防止系统因为访问热点数据的请求过多而崩溃。
4.缓存穿透、缓存击穿和缓存雪崩的区别是什么,如何预防它们?
- 缓存穿透是指用户不断请求缓存和数据库中都不存在的数据,导致所有的请求都直接打到数据库上,从而可能导致数据库压力过大。预防方法包括:对用户输入的查询条件进行校验;对查询结果为空的情况也进行缓存,但设置较短的过期时间。
- 缓存击穿是指一个热点数据的缓存突然失效(比如过期),导致大量的请求直接打到数据库上。预防方法包括:对热点数据设置永不过期;使用互斥锁或者队列,保证对数据库的访问只有一个线程在进行。
- 缓存雪崩是指在缓存系统中,大量的数据突然在同一时间点失效,导致大量的请求都直接打到数据库上。预防方法包括:对缓存的过期时间进行随机化,避免大量数据同时过期;使用多级缓存,或者容错备份方法;服务降级,即在缓存失效时,让用户访问备份数据或者返回简化的内容。
5.如何保证缓存数据的一致性?
在使用缓存的系统中,保持缓存数据和数据库数据的一致性是一个重要,也是相当复杂的问题。以下是一些常用的策略:
- 读写穿透: 所有的写操作都直接对数据库进行,并且在写入数据库后,立即从数据库读取数据更新缓存。这种方式可以保证缓存数据的一致性,但可能会增加数据库的压力。
- 延时双删: 在更新数据库后,延时一段时间(比如几百毫秒),然后删除缓存。这种方式可以在大部分情况下保证数据的一致性,但在高并发情况下可能会有问题。
- 消息队列: 使用消息队列,将更新操作作为消息发送到队列,然后由单独的线程或进程进行处理。这种方式可以序列化更新操作,避免并发更新导致的一致性问题。
- 版本号(或时间戳)机制: 为每个数据项添加版本号或时间戳,只有当缓存中的版本号和数据库中的版本号一致时,才更新缓存。这种方式可以有效防止旧数据覆盖新数据,从而保证数据的一致性。
6.分布式缓存系统有哪些常见的实现,如Redis,Memcached等,它们的优缺点是什么?
以下是两种常见的分布式缓存系统,以及它们各自的优缺点:
- Redis:优点:Redis 是一个开源的,基于内存的键值存储系统。它支持多种数据结构,如字符串,哈希,列表,集合,有序集合等。此外,Redis 还支持数据持久化,可以将内存中的数据保存在磁盘中,重启后可以再次加载到内存中。Redis 还支持分布式,可以实现主从同步,分片等功能。缺点:虽然 Redis 支持数据持久化,但是如果数据非常重要,且不能接受数据丢失,那么可能需要考虑其他持久化的存储系统。同时,虽然 Redis 支持分布式,但是其分片和一致性方面的功能不如一些专门的分布式系统强大。
- Memcached:优点:Memcached 是一个开源的,高性能的,分布式内存对象缓存系统。它简单易用,使用广泛,有丰富的客户端库支持。Memcached 非常适合用于缓存数据库查询结果,页面渲染结果等。缺点:Memcached 的数据模型比较简单,只支持简单的键值对,并且不支持数据持久化。如果需要复杂的数据结构或者数据持久化,那么可能需要考虑其他缓存系统。
7.为什么在高并发环境下,数据库需要配合缓存来使用?
在高并发环境下,如果所有的请求都直接访问数据库,可能会使数据库的负载过大,影响数据库的性能,甚至导致数据库崩溃。在这种情况下,使用缓存是一种有效的方式来提高系统性能,减轻数据库负载:
- 减少数据库压力: 缓存可以把一部分读请求从数据库转移到内存,从而减轻数据库的压力。对于读多写少的系统,通过合理的缓存策略,大部分的读请求可以直接在缓存中得到满足,极大地减少了数据库的访问压力。
- 提高系统响应速度: 访问内存的速度要远高于访问磁盘(数据库通常存储在磁盘上)的速度。因此,缓存可以显著提高系统的响应速度,提高用户体验。
- 缓冲数据库峰值访问: 在高并发场景下,流量可能会有突发的峰值。缓存可以作为一个缓冲层,吸收峰值流量,保护数据库不会被突然的流量冲垮。
- 减少网络带宽: 缓存一般部署在与应用服务器相同或者网络距离较近的地方,通过缓存,可以减少对数据库的远程访问,从而节省网络带宽。
8.在高并发系统中,如何有效地更新缓存?
在高并发系统中,有效地更新缓存是一个挑战,因为你需要在保持数据一致性和提高性能之间找到平衡。以下是一些常用的策略:
- 懒惰更新或者延迟更新: 当数据发生改变时,不立即更新缓存,而是在下次获取数据时,从数据库获取最新的数据,并更新缓存。这种方法简单易实现,但可能导致数据不一致。
- 立即更新或者同步更新: 当数据发生改变时,立即更新缓存。这种方法可以保持数据的一致性,但可能会影响性能,因为每次数据更新都需要同时更新数据库和缓存。
- 设置适当的缓存过期时间: 为缓存设置一个过期时间,当缓存过期时,再从数据库获取最新的数据。这种方法可以在一定程度上平衡数据一致性和性能。
- 使用消息队列: 当数据发生改变时,将更新操作发送到消息队列,然后由一个专门的线程或者进程从队列中取出操作并更新缓存。这种方法可以将更新操作异步化,提高性能。
- 使用读写分离和数据库主从同步: 将写操作直接发送到数据库,读操作从缓存中获取。当数据库中的数据发生改变时,通过数据库主从同步更新缓存。这种方法需要数据库支持主从同步,实现较为复杂。
9.为什么在高并发系统中,我们通常推荐使用分布式缓存而不是本地缓存?
在高并发系统中,我们通常推荐使用分布式缓存而不是本地缓存,主要基于以下几个原因:
- 可伸缩性: 分布式缓存由多个节点组成,可以通过增加节点来提高整体的存储容量和处理能力。这与单机的本地缓存形成对比,本地缓存的容量和性能受到单台机器的硬件限制。
- 数据一致性: 在分布式环境中,多个应用实例可能需要访问和修改同一份数据。如果使用本地缓存,每个应用实例只能看到自己的缓存,无法看到其他实例的缓存,这可能导致数据不一致。分布式缓存可以提供一致的数据视图,所有的应用实例共享同一份缓存数据。
- 高可用性: 分布式缓存通常可以提供数据复制和故障转移的机制,当某个缓存节点出现故障时,可以自动切换到其他健康的节点,提供持续的服务。而本地缓存通常无法提供这样的机制。
- 网络延迟: 本地缓存由于在本地,访问延迟低。但在微服务架构下,服务实例可能分布在不同的网络节点,如果频繁访问远程的数据库,网络延迟可能会成为瓶颈。使用分布式缓存,可以将数据近距离存储在服务实例附近,减少网络延迟。
总的来说,在高并发和大规模的系统中,分布式缓存通常比本地缓存更具优势。但是,这并不意味着本地缓存没有用武之地,对于某些特定的场景,如数据局部性强,或者对延迟要求极高的场景,本地缓存可能是更好的选择。
10.在使用缓存改善高并发系统的性能时,有哪些常见的最佳实践?
选择合适的缓存策略:不同的缓存策略适用于不同的场景。例如,LRU(最近最少使用)策略适用于那些最近访问过的数据可能再次被访问的场景,而LFU(最少使用)策略适用于一些访问频率较高的数据。
缓存数据的过期和清理:设置合理的过期时间可以防止缓存中的数据过时。此外,定期清理缓存中的无用数据也是一个好习惯。
分布式缓存:在高并发系统中,单点缓存可能会成为瓶颈。使用分布式缓存(比如Redis、Memcached)可以提高缓存系统的吞吐量和可用性。
一致性哈希:一致性哈希是一种特殊的哈希技术,常常与分布式缓存一起使用,以减少节点增加或减少时对系统的影响。
缓存穿透、击穿和雪崩的防护:这些都是缓存系统中常见的问题,需要通过各种策略进行防护。比如,对于缓存穿透,可以使用布隆过滤器;对于缓存击穿,可以使用互斥锁;对于缓存雪崩,可以使用多级缓存、设置不同的过期时间等。
读写策略:缓存的读写策略(如:Read/Write through, Read/Write around, Read/Write back)也需要根据具体的业务需求来选择。
监控和日志:对缓存的命中率、响应时间等关键指标进行监控,可以帮助系统管理员及时发现并处理问题。同时,保持良好的日志记录也可以帮助分析和解决问题。
测试:在推出任何缓存策略之前,都应该进行充分的测试,包括但不限于性能测试和压力测试,确保缓存策略能够在实际环境中有效工作。
 微信
微信- 支付宝




