
谷粒商城-es篇
Docker
删掉容器,之前的数据会不会没有。
不会的,因为删除之前数据就保存在外部,重新映射就行
docker stop id
docker rm id
docker restart id
安装es和kinana
# 1.拉取镜像,es存储检索 kibana主要提供可视化的操作 |
分词器
sudo docker exec -it elasticsearch /bin/bash |
安装nginx
docker pull nginx:1.10 |
基础语法
nested
克服扁平化处理的副作用。
Java代码
Jrebel配置
需要在:帮助->VM进行下面配置。
-Drebel.base=D:\JAVA\Jrebel
-Duser.home=D:\JAVA\Jrebel
thmleft
页面修改实时更新
正向代理与反向代理
正向:科学上网,隐藏客户端信息
反向:屏蔽内网信息,负载均衡访问
nginx 进行反向代理
所有来自于gulimall.com的请求,都转到商品服务。
查看日志
docker logs nginx
:set number #显示行号
nginx 反向代理成功
我使用的是虚拟机部署nginx ,不是docker部署。
监听80端口,设置proxy_pass代理.
进入安装好的目录 /usr/local/nginx/sbin
./nginx 启动
./nginx -s stop 快速停止
./nginx -s quit 优雅关闭,在退出前完成已经接受的连接请求
./nginx -s reload 重新加载配置
查看端口号:
netstat -ntlp
docker run -p 80:80 –name nginx -v /mydata/nginx/html:/usr/share/nginx/html -v /mydata/nginx/logs:/var/log/nginx -v /mydata/nginx/conf:/etc/nginx -d nginx:1.10
、安装nginx
随便启动一个 nginx 实例,只是为了复制出配置
docker run -p 80:80 –name nginx -d nginx:1.10
将容器内的配置文件拷贝到当前目录:docker container cp nginx:/etc/nginx .
别忘了后面的点
修改文件名称:mv nginx conf 把这个 conf 移动到/mydata/nginx 下
终止原容器:docker stop nginx
执行命令删除原容器:docker rm $ContainerId
创建新的 nginx;执行以下命令
执行前确保上面的步骤执行了 创建了相关的配置文件 否则nginx无法启动
docker run -p 80:80 –name nginx
-v /mydata/nginx/html:/usr/share/nginx/html
-v /mydata/nginx/logs:/var/log/nginx
-v /mydata/nginx/conf:/etc/nginx
-d nginx:1.10
docker ID update –restart=always
P141- 性能压测
内存泄漏和并发与同步问题
内存泄漏指的是程序在使用完内存后,没有释放它们,导致程序占用的内存越来越多,最终可能导致程序崩溃或者性能下降。
并发与同步是指在多线程或多进程的程序中,如何确保不同部分的代码在资源访问上不会产生冲突,保证程序的正确性和稳定性。
对于压力测试:
重复性:测试应该可以重复执行,以便确认结果的一致性。
并发性:测试应该模拟多个用户或多个请求同时访问系统,以检查系统在负载下的性能表现。
量级:测试应该覆盖各种量级,以确保系统在不同规模下的稳定性和性能。
随机变化:通过引入随机性来模拟真实世界中的情况,以便发现系统可能存在的隐性问题。
性能指标
- 响应时间(Response Time):从发送请求到接收到响应的时间间隔。通常用毫秒(ms)或秒(s)来衡量。
- 吞吐量(Throughput):单位时间内处理的请求数量或事务数量。通常用每秒请求数(Requests Per Second,RPS)或每秒事务数(Transactions Per Second,TPS)来衡量。
- 并发用户数(Concurrent Users):同时访问系统的用户数量。对于网站或应用程序来说,这是一个重要的指标,影响着系统的性能。
- CPU 使用率(CPU Utilization):CPU 在单位时间内被使用的百分比。高 CPU 使用率可能表示系统负载较高。
- 内存使用率(Memory Utilization):内存在单位时间内被使用的百分比。高内存使用率可能导致内存泄漏或需要优化。
- 网络延迟(Network Latency):数据在网络中传输的时间。通常用毫秒(ms)来衡量。
- 错误率(Error Rate):处理过程中出现错误的比例。这可以包括HTTP错误码、异常等。
- 资源利用率(Resource Utilization):其他硬件或软件资源(如数据库连接、磁盘I/O)的使用情况。
- 稳定性和可靠性(Stability and Reliability):系统在一段时间内保持稳定和可靠的能力。
- 容量(Capacity):系统可以支持的最大负载或数据量。
- 页面加载时间(Page Load Time):网页从请求开始到完全加载完成的时间。
- 事务成功率(Transaction Success Rate):完成的事务中成功的比例。
- 队列长度(Queue Length):等待处理的请求或任务数量。
- 数据吞吐量(Data Throughput):单位时间内处理的数据量,通常用于数据库或存储系统。
P142 性能压测-压力测试-Apache JMeter安装使用
- 加大运行内存
结果分析
1、有错误率同开发确认,确定是否允许错误的发生或者错误率允许在多大的范围内;
2、 Throughput 吞吐量每秒请求的数大于并发数,则可以慢慢的往上面增加;若在压测的机 器性能很好的情况下,出现吞吐量小于并发数,说明并发数不能再增加了,可以慢慢的 往下减,找到最佳的并发数;
3、压测结束,登陆相应的 web 服务器查看 CPU 等性能指标,进行数据的分析;
4、最大的 tps,不断的增加并发数,加到 tps 达到一定值开始出现下降,那么那个值就是 最大的 tps。
5、最大的并发数:最大的并发数和最大的 tps 是不同的概率,一般不断增加并发数,达到 一个值后,服务器出现请求超时,则可认为该值为最大的并发数。
6、压测过程出现性能瓶颈,若压力机任务管理器查看到的 cpu、网络和 cpu 都正常,未达到 90%以上,则可以说明服务器有问题,压力机没有问题。
7、影响性能考虑点包括: 数据库、应用程序、中间件(tomact、Nginx)、网络和操作系统等方面
8、首先考虑自己的应用属于 CPU 密集型还是 IO 密集型
docker stats #命令可以监听dockers容器中的每一个容器的内存情况
P144 对内存与垃圾回收
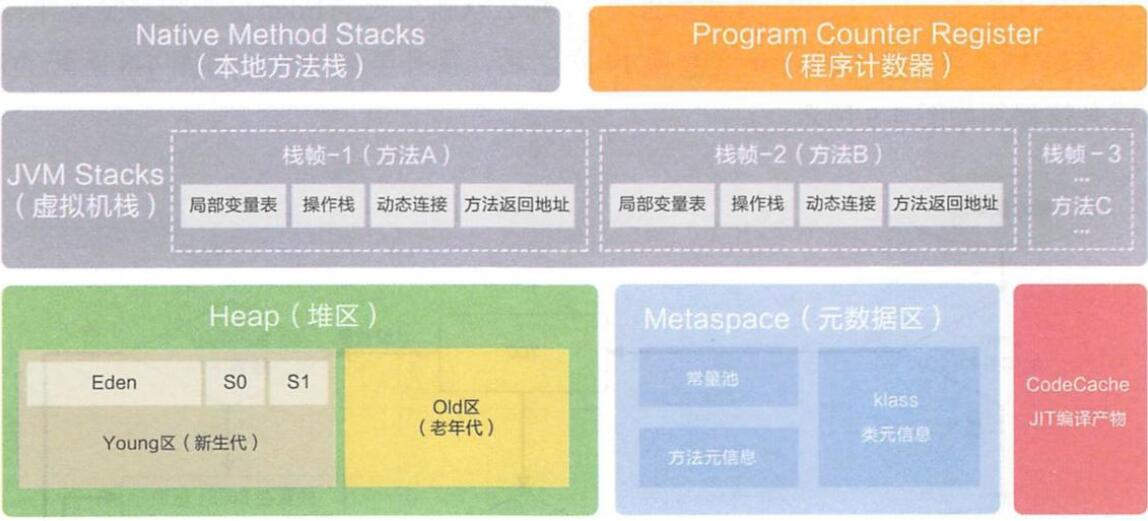
程序计数器
记录的是正在执行的虚拟机字节码指令的地址,
此内存区域是唯一一个在JAVA虚拟机规范中没有规定任何OutOfMemoryError的区域
虚拟机
描述的是 JAVA 方法执行的内存模型,每个方法在执行的时候都会创建一个栈帧, 用于存储局部变量表,操作数栈,动态链接,方法接口等信息
局部变量表存储了编译期可知的各种基本数据类型、对象引用
虚拟机栈是线程隔离的,即每个线程都有自己独立的虚拟机栈
本地方法栈类似于虚拟机栈,只不过本地方法栈使用的是本地方法
堆
几乎所有的对象实例都在堆上分配内存,所有的对象实例以及数组都要在堆上分配。堆是垃圾收集器管理的主要区域,也被称为“GC 堆”;
也是我们优化最多考虑的地方。
分为老年代和新生代,Java8引入了元空间,替换了新生代,元空间里面存储的是整个类。
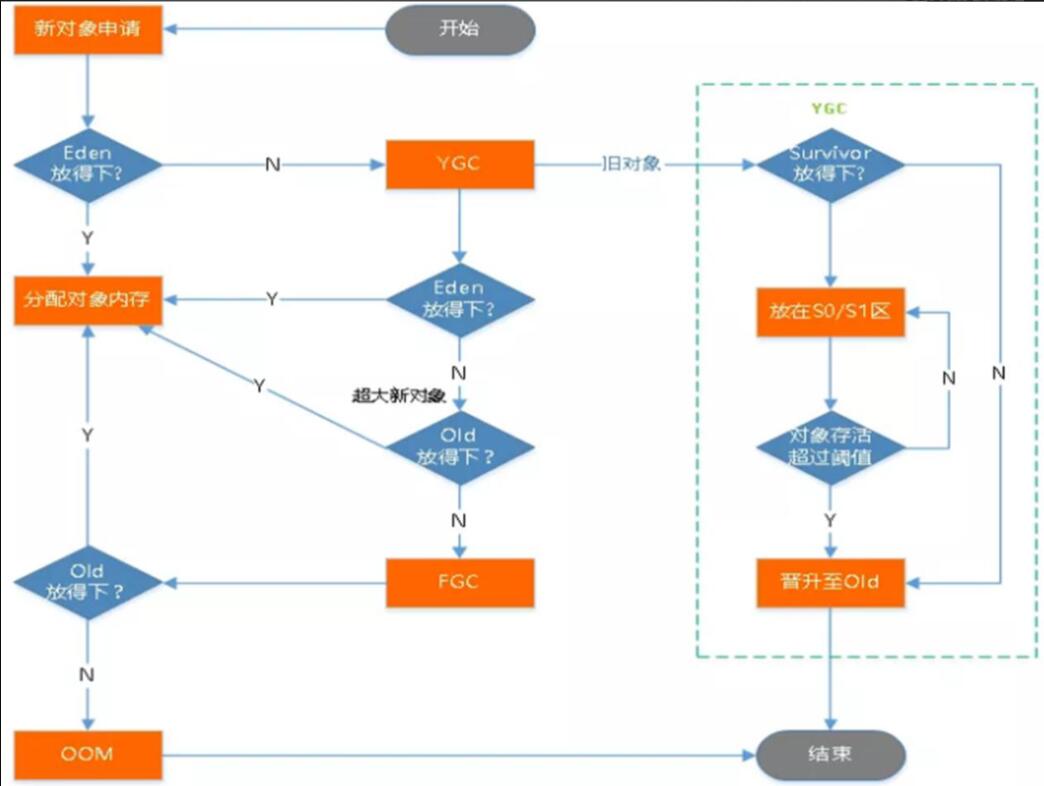
OOM
内存不够了,存不下东西了。
FULL GC
是指一种全局性的垃圾回收,它会尝试回收整个堆内存中的所有对象,包括年轻代和老年代的对象。
FULL GC 通常发生在以下情况下:
老年代空间不足:当老年代无法容纳新对象时,会触发一次 FULL GC,尝试回收老年代的内存。
永久代或元空间空间不足:在早期的JVM版本中,当永久代(Permanent Generation)无法容纳新的类元信息时,会触发 FULL GC。在JDK 8及之后版本中,类元信息存储在元空间(Metaspace)中,FULL GC通常发生在元空间耗尽本地内存时。
显式调用:程序员可以通过调用
System.gc()或者使用诸如G1垃圾回收器的jcmd命令来触发 FULL GC。**CMS回收器中的”Concurrent Mode Failure”**:在CMS(Concurrent Mark and Sweep)回收器中,如果并发标记过程中老年代空间不足,将触发 FULL GC。
FULL GC 是一种代价高昂的操作,因为它会暂停整个应用程序的运行,导致停顿时间较长,可能会影响应用程序的响应性能。因此,尽管 FULL GC 是必要的,但尽量避免频繁触发 FULL GC 对于保持应用程序的稳定性和性能是很重要的。
总结:老年代空间不足,新生代或者元空间内存不足,或者直接调用,都可以触发FGC。
P145 小工具说明
jconsole
如果你的电脑,全局配置了JDK,
直接win+r, >jconsole ,
jvisualvm
这个是上面的升级版
监控内存泄露,跟踪垃圾回收,执行时内存、cpu 分析,线程分析…
P146 中间件指标
- 当前正在运行的线程数不能超过设定的最大值。一般情况下系统性能较好的情况下,线 程数最小值设置 50 和最大值设置 200 比较合适。
- 当前运行的 JDBC 连接数不能超过设定的最大值。一般情况下系统性能较好的情况下, JDBC 最小值设置 50 和最大值设置 200 比较合适。
- GC频率不能频繁,特别是 FULL GC 更不能频繁,一般情况下系统性能较好的情况下,JVM 最小堆大小和最大堆大小分别设置 1024M 比较合适。
数据库指标
- SQL 耗时越小越好,一般情况下微秒级别。
- 命中率越高越好,一般情况下不能低于 95%。
- 锁等待次数越低越好,等待时间越短越好。
JVM 分析 & 调优
jvm 调优,调的是稳定,并不能带给你性能的大幅提升。服务稳定的重要性就不用多说了,保证服务的稳定,gc 永远会是 Java
程序员需要考虑的不稳定因素之一。复杂和高并发下的服务,必须保证每次 gc 不会出现性能下降,各种性能指标不会出现波动,gc 回收规律而且 干净,找到合适的
jvm 设置。Full gc 最会影响性能,根据代码问题,避免 full gc 频率。可以适当调大年轻代容量,让大对象可以在年轻代触发 yong
gc,调整大对象在年轻代的回收频次,尽可能保证大对象在年轻代回收,减小老年代缩短回收时间;
优化吞吐量
- 中间件越多,性能损失越大,大多都损失在网络交互了;
- Db(MySQL 优化)
- 模板的渲染速度(缓存)
- 静态资源
nginx动静分离
把静态资源都放在Nginx那里,减轻服务的压力。
- Xmx:设置堆的最大大小
- Xms:设置堆的初始大小
- Xmn:设置堆的新生代大小
优化三级分类获取数据
优化前
对二级菜单的每次遍历都需要查询数据库,浪费大量资源
优化后
仅查询一次数据库,剩下的数据通过遍历得到并封装
P151 本地缓存-分布式缓存
在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。
P153 修改三级缓存
|
P154 内存溢出问题及其解决方案
内存溢出:OutOfDirectMemoryError
解决方案:更换客户端
<dependency> |
P155 缓存击穿-穿透-雪崩
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null
写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决方案:
缓存空结果、并且设置短的过期时间。
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决方案:
原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存击穿
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所 有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
解决方案:
加锁
P156 加锁解决缓存击穿问题
本地锁
使用本地锁解决缓存击穿的问题,如果是一个单体应用,我们可以用本地锁:synchronized,JUC(Lock),并且锁也是单列的,比如如果用synchronized (this){ } 来加锁,这个this必须是单列的否则无法锁住,在分布式情况下,想要锁住所有,必须使用分布式锁。
//从数据库查询并封装分类数据 |
我们在获取锁之后立马再去查询一次缓存,此时没有在去查询数据库,查询数据之后在把数据放入缓存,然后才能释放锁。
P157 本地锁在分布式下的问题
锁
public class LockExample { |
原子性
原子性是指一个操作是不可分割的单元,要么完全执行,要么完全不执行。在多线程环境中,原子性可以保证某些操作不会被中断,从而避免了竞态条件和并发问题。
IDEA创建三个运行实例,修改一下端口号即可,然后都跑一下,运行三个实例,然后测试,要用nginx转发网关,显然这个三个实列都会查一次。。
本地锁,只能锁住当前进程,所以我们需要分布式锁。
P157 分布式锁原理与使用
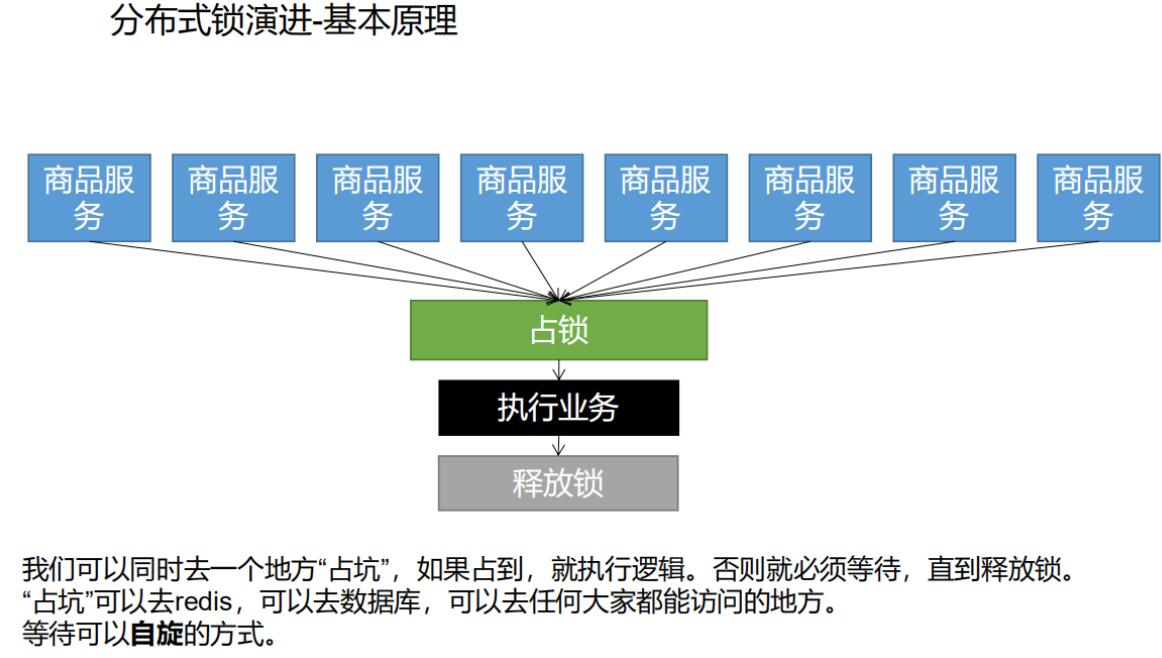
先去占位,占到就执行逻辑,占不到就等待,方法
自旋。
乐观锁
- 多个客户端尝试获取锁,可以同时去一个公共地方(如 Redis、数据库)占坑。
- 如果占坑成功,表示获取了锁,可以执行后续逻辑。
- 如果占坑失败,表示锁已经被其他客户端占用,等待一段时间后再次尝试。
死锁
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() { |
分布式锁
setnx占好了位,业务代码异常或者程序在页面过程中宕机。没有执行删除锁逻辑,这就造成了死锁。
解决: 设置锁的自动过期,即使没有删除,会自动删除。
setnx设置好,正要去设置过期时间,宕机。又死锁了。
解决:设置过期时间和占位必须是原子的。 使用setnx ex
如果由于业务时间很长,锁自己过期了,我们直接删除,有可能把别人正在持有的锁删除了。
解决:占锁的时候,值指定为uuid, 每个人匹配是自己的锁才删除。
如果正好判断是当前值,正要删除锁的时候,锁已经过期,别人已经设置到了新的值。那么我们删除的是别人的锁。
删除锁必须保证原子性。使用redis+Lua脚本完成。
if redis.call("get", KEYS[1]) == ARGV[1] then |
总结:保证加锁[占位+过期时间]和删除锁[判断+删除]的原子性。更难的事情,锁的自动续期。
手写代码:
public Map<String, List<Catelog2Vo>> getCatalogJson() { |
setnx 与 ex
SETNX: 用于设置一个键的值,但只在该键不存在的情况下才进行设置。如果键已经存在,那么SETNX命令将不会做任何操作。EX: 用于为键设置过期时间。可以与SET命令一起使用,以设置键的值并为其设置过期时间。SET key value EX 10
并发与并行
并发强调多个任务能够交替执行,而并行强调多个任务同时执行。
P161、缓存-分布式锁
可重入锁
当一个线程在持有锁的情况下,可以多次进入同步代码块或方法,而不会被阻塞,这个特性就叫做可重入(或递归)锁。这意味着线程可以反复地获得同一个锁,而不会因为自己已经持有锁而被阻塞。
public class Example { |
锁的续期
大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内
部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。
异步
允许程序在进行某些耗时操作时不必等待操作完成,而是可以继续执行其他任务。在异步模型中,任务的执行不会阻塞程序的主线程,而是通过回调、事件处理等机制来处理任务的完成或者错误。
看门狗()
自动延长锁的时间
// 加锁以后10秒钟自动解锁,看门狗不续命 |
异步锁
lockAsync()方法会异步地获取锁,如果成功获取锁,返回一个Future对象,可以通过该对象来获取锁的状态。lockAsync(10, TimeUnit.SECONDS)会在最多等待10秒的情况下异步获取锁,如果在指定时间内成功获取锁,也会返回一个Future对象。tryLockAsync(100, 10, TimeUnit.SECONDS)会尝试在最多等待100毫秒的情况下异步获取锁,如果在指定时间内成功获取锁,也会返回一个Future对象,Future的结果会是一个布尔值,表示是否成功获取锁。
RLock对象完全符合Java的Lock规范。也就是说只有拥有锁的进程才能解锁
P162
tryLock() 和 lock()
tryLock()是非阻塞的,它会立即返回获取锁的结果;- 而
lock()是阻塞的,如果锁被其他线程占用,它会一直等待直到获取到锁为止。
读写锁
- 读锁:允许多个线程同时获得锁并读取共享资源,但在读取期间不允许其他线程获取写锁。读锁可以提高并发读取性能,适用于读操作频繁的场景。
- 写锁:只允许一个线程获得锁并对共享资源进行写操作,其他线程在此期间无法获取读锁或写锁。写锁用于保护写操作的原子性和一致性。
基本案例:
|
P164 闭锁测试
闭锁
/** |
P165 信号量测试
可以用于限流场景,一个请求过来先获取一个信号,比如设置了1000个则1000个请求完必须先等其他的释放之后才能操作。
信号量为存储在redis中的一个数字,当这个数字大于0时,即可以调用acquire()方法增加数量,也可以调用release()方法减少数量,但是当调用release()之后小于0的话方法就会阻塞,直到数字大于0
RSemaphore 是 Redisson 提供的分布式信号量(Semaphore)实现。
semaphore.acquire():获取信号量,如果当前可用的信号量数量不足,则会阻塞等待直到可以获取到信号量。semaphore.acquireAsync():异步获取信号量,如果当前可用的信号量数量不足,则会异步等待直到可以获取到信号量。semaphore.acquire(int permits):获取指定数量的信号量,参数permits指定了需要获取的信号量数量。semaphore.tryAcquire():尝试获取信号量,如果当前可用的信号量数量足够,则会立即返回true,否则返回false。semaphore.tryAcquireAsync():异步尝试获取信号量,如果当前可用的信号量数量足够,则会立即返回true,否则返回false。semaphore.tryAcquire(int permits, long waitTime, TimeUnit unit):在指定的等待时间内尝试获取信号量,如果在等待时间内能够获取到信号量,则返回true,否则返回false。semaphore.tryAcquireAsync(int permits, long waitTime, TimeUnit unit):异步在指定的等待时间内尝试获取信号量,如果在等待时间内能够获取到信号量,则返回true,否则返回false。semaphore.release(int permits):释放指定数量的信号量,参数permits指定了需要释放的信号量数量。semaphore.release():释放一个信号量。semaphore.releaseAsync(int permits):异步释放指定数量的信号量,参数permits指定了需要释放的信号量数量。semaphore.releaseAsync():异步释放一个信号量。
P166 缓存一致性问题
如果数据库中的某条数据,放入缓存之后,又立马被更新了,那么该如何更新缓存呢?
解决方案
先写缓存,再写数据库
先写数据库,再写缓存
先删缓存,再写数据库
先写数据库,再删缓存
使用第四种方法。
P167 SpringCache
整合SpringCache简化缓存开发
1)、引入依赖spring-boot-starter-cache、spring-boot-starter-data-redis2)、写配置(1)、自动配置了哪些CacheAuroConfiguration会导入 RedisCacheConfiguration;自动配好了缓存管理器RedisCacheManager(2)、配置使用redis作为缓存spring.cache.type=redis3)、测试使用缓存@Cacheable: Triggers cache population.:触发将数据保存到缓存的操作@CacheEvict: Triggers cache eviction.:触发将数据从缓存删除的操作@CachePut: Updates the cache without interfering with the method execution.:不影响方法执行更新缓存@Caching: Regroups multiple cache operations to be applied on a method.:组合以上多个操作@CacheConfig: Shares some common cache-related settings at class-level.:在类级别共享缓存的相同配置1)、开启缓存功能 @EnableCaching2)、只需要使用注解就能完成缓存操作4)、原理:CacheAutoConfiguration -> RedisCacheConfiguration ->自动配置了RedisCacheManager->初始化所有的缓存->每个缓存决定使用什么配置->如果redisCacheConfiguration有就用已有的,没有就用默认配置->想改缓存的配置,只需要给容器中放一个RedisCacheConfiguration即可->就会应用到当前RedisCacheManager管理的所有缓存分区中
/** |
P172 Spring-Cache的不足
1)、读模式:
缓存穿透:查询一个null数据。解决:缓存空数据;ache-null-values=true
缓存击穿:大量并发进来同时查询一个正好过期的数据。解决:加锁;?默认是无加锁的;sync = true(加锁,解决击穿)
缓存雪崩:大量的key同时过期。解决:加随机时间。加上过期时间。:spring.cache.redis.time-to-live=3600000
2)、写模式:(缓存与数据库一致)
1)、读写加锁。
2)、引入Canal,感知到MySQL的更新去更新数据库
3)、读多写多,直接去数据库查询就行
锁
本地锁
用于控制多个并发执行的线程或进程之间的访问和共享资源。
全局锁(Global Lock):
- 全局锁是在整个系统范围内起作用的锁,通常用于保护对全局资源的访问,例如数据库表、文件等。在分布式环境中,全局锁可能需要通过分布式锁来实现。
分布式锁(Distributed Lock):
- 分布式锁用于在分布式系统中控制多个节点对共享资源的访问。它能够确保在不同节点上的多个线程或进程之间的互斥访问。常见的实现方式包括基于数据库、基于缓存(如Redis)、基于ZooKeeper等。
悲观锁和乐观锁:
- 悲观锁认为并发访问会导致数据冲突,因此在访问之前先获取锁,确保只有一个线程或进程能够访问。乐观锁则假设并发访问不会导致冲突,但在更新时会检查是否发生了冲突。
读写锁(Read-Write Lock):
- 读写锁允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这样可以提高读操作的并发性。
自旋锁(Spin Lock):
- 自旋锁是一种忙等待锁,在尝试获取锁时,如果锁被占用,线程会一直循环等待直到锁被释放。适用于短时间内锁被占用的情况。
公平锁和非公平锁:
- 公平锁会按照线程请求锁的顺序依次获取,保证线程的公平性。非公平锁则不考虑等待队列的顺序,有可能会导致某些线程一直获取不到锁。
CAS(Compare and Swap):
- CAS 是一种乐观锁的实现方式,通过比较当前内存中的值和期望值是否相等,如果相等则进行更新。它是一种基于硬件的原子操作,常用于实现非阻塞算法。
可重入锁(Reentrant Lock):
- 可重入锁允许一个线程在持有锁的情况下再次获取锁,避免死锁情况。
读写锁(Reentrant ReadWriteLock):
- 读写锁包括读锁和写锁,允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。
偏向锁、轻量级锁和重量级锁:
- 这是JVM对对象锁的优化实现。偏向锁会假设锁一直是被单一线程访问的,如果多次访问,则会升级为轻量级锁,再次竞争失败会升级为重量级锁。
这些锁都有各自的应用场景和特点,根据实际情况选择合适的锁机制是非常重要的。
bug日志
8-25日,8:20,es配置好了,卡了10天。
9-25日,开始学习谷粒商城,从P139开始学习,目前遇到的困难是:nginx 搞不明白。
 微信
微信- 支付宝



